Update Log merupakan catatan pembaruan feidlambda. Berikut catatan perubahan/pembaruan secara umum beserta penjelasan perubahan/pembaruan. Untuk perubahan berdasarkan fungsinya, bisa dilihat di bagian Changelog.
Update v0.3.1 (2022-01-13)
Pada fungsi FILTER_MINMAX_ARRAY() terdapat argumen opsional baru yaitu take_first_only. Jika take_first_only = TRUE, maka hasil filter minimum/maksimum hanya mengambil baris pertamanya saja (jika terdapat minimum/maksimum lebih dari satu baris).
Pada fungsi SWAP_*(), nilai argumen from_index dan to_index menerima index negatif (indeks dari belakang). Bersamaan perubahan tersebut, nilai defaultto_index menjadi -1 yang artinya secara default (tanpa argumen) fungsi SWAP_*() menukar posisi terdepan dengan terbelakang (baik berdasarkan baris ataupun kolom).
Perubahan nama argumen pada beberapa fungsi seperti:
FILTER_MINMAX_COLUMN(): col -> column_index, with_lables -> with_label.
Fungsi TEXT_SPLIT_VECTOR() menggunakan metode recursive dari fungsi TEXTSPLIT().
Pada fungsi TEXT_SPLIT_VECTOR() terdapat argumen opsional baru yaitu replace_na, yang berfungsi untuk mengubah nilai #NA dari hasil akhir.
Tambahan informasi limitasi pada fungsi TEXT_SPLIT_VECTOR().
Fungsi feidlambda v0.3.x
Pada feidlambda v0.3.x, setiap fungsi dikategorikan sesuai kegunaannya. Berikut kategori yang tersedia di feidlambda v0.3.x:
FILTER_*: Melakukan filtering atau subsetting (memilah) dari data.
GET_*: Mengambil informasi dari data.
IS_*: Fungsi logical tambahan.
MAKE_*: Membangkitkan data.
REPEAT_*: Mengulangi/merepetisi data.
RESHAPE_*: Mengubah dimensi data.
ROTATE_*: Merubah posisi data dengan diputar.
SWAP_*: Menukar posisi data.
TEXT_*: Fungsi tambahan yang berkaitan dengan teks.
Download excel demonstrasi RELEASE_feidlambda_v0_3_1.xlsx, untuk memudahkan mengeksplorasi fungsi baru di feidlambda v0.3.x.
Catatan
Gambar yang ditampilkan pada halaman ini merupakan dari versi sebelumnya (feidlambda v0.3.0) dan tidak diperbarui untuk setiap update. Oleh karena itu, disarankan untuk mengeksplorasi langsung dari dokumen yang telah dilampirkan.
Kategori FILTER_*
Kategori FILTER_* merupakan kumpulan fungsi yang melakukan filtering atau subsetting (memilah) data berupa vector ataupun array. Hubungan antar fungsi di kategori ini bisa dilihat di Gambar 3.1.
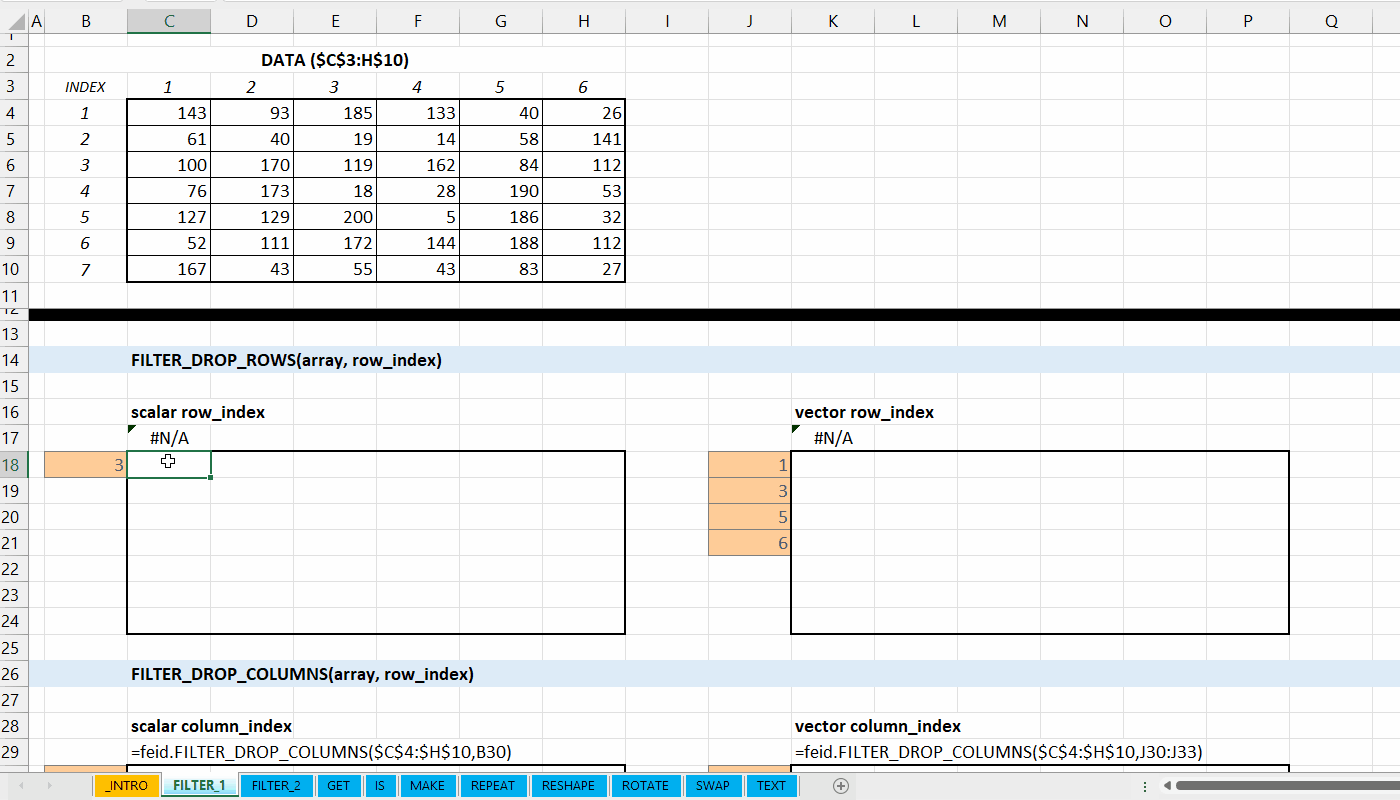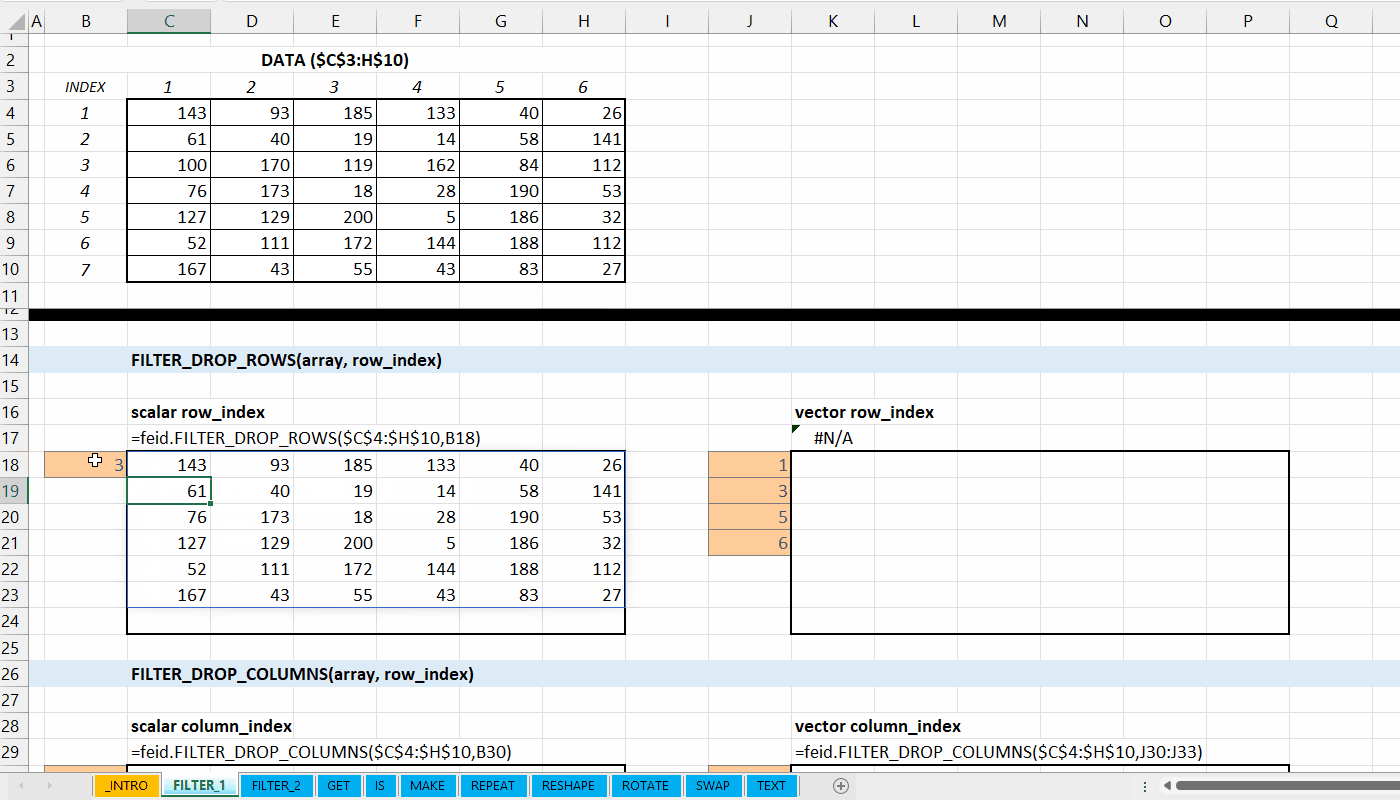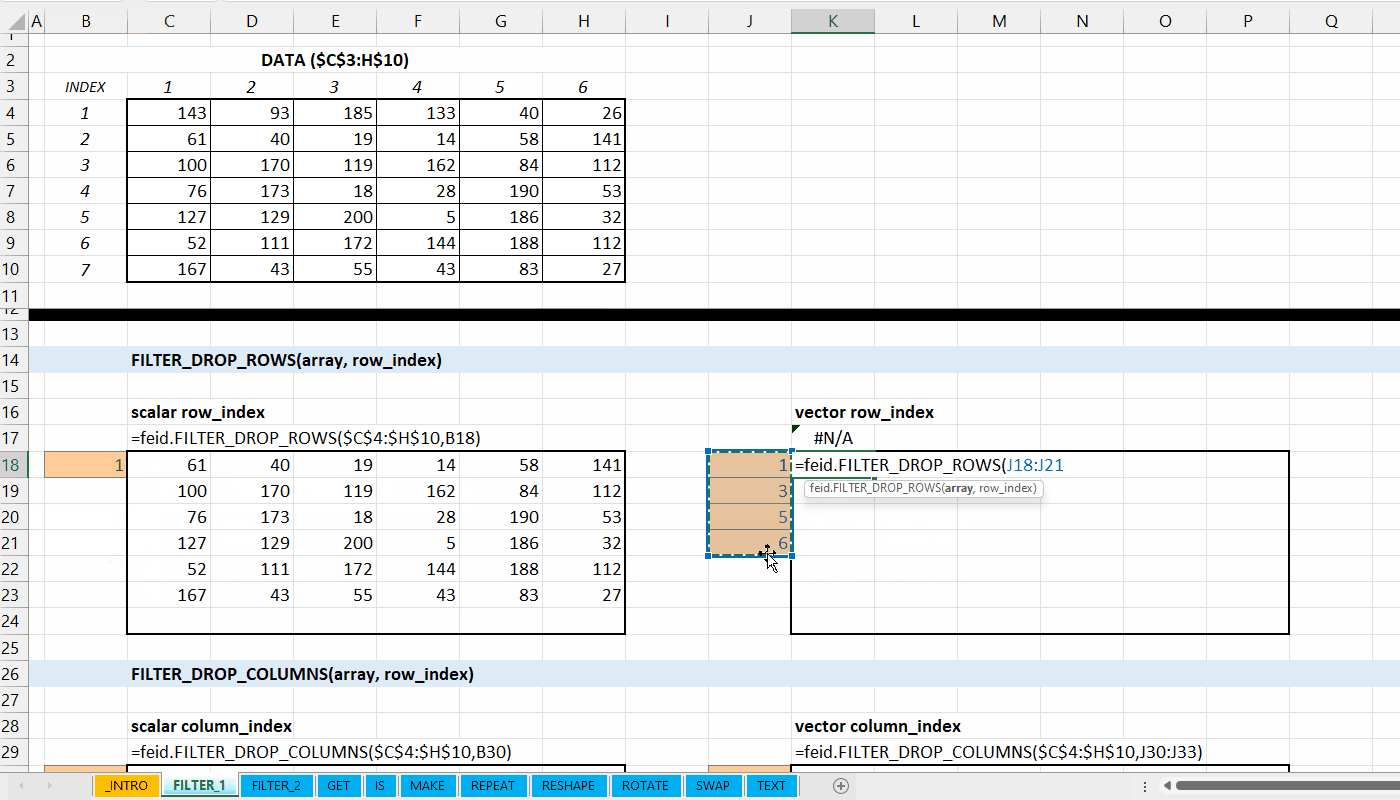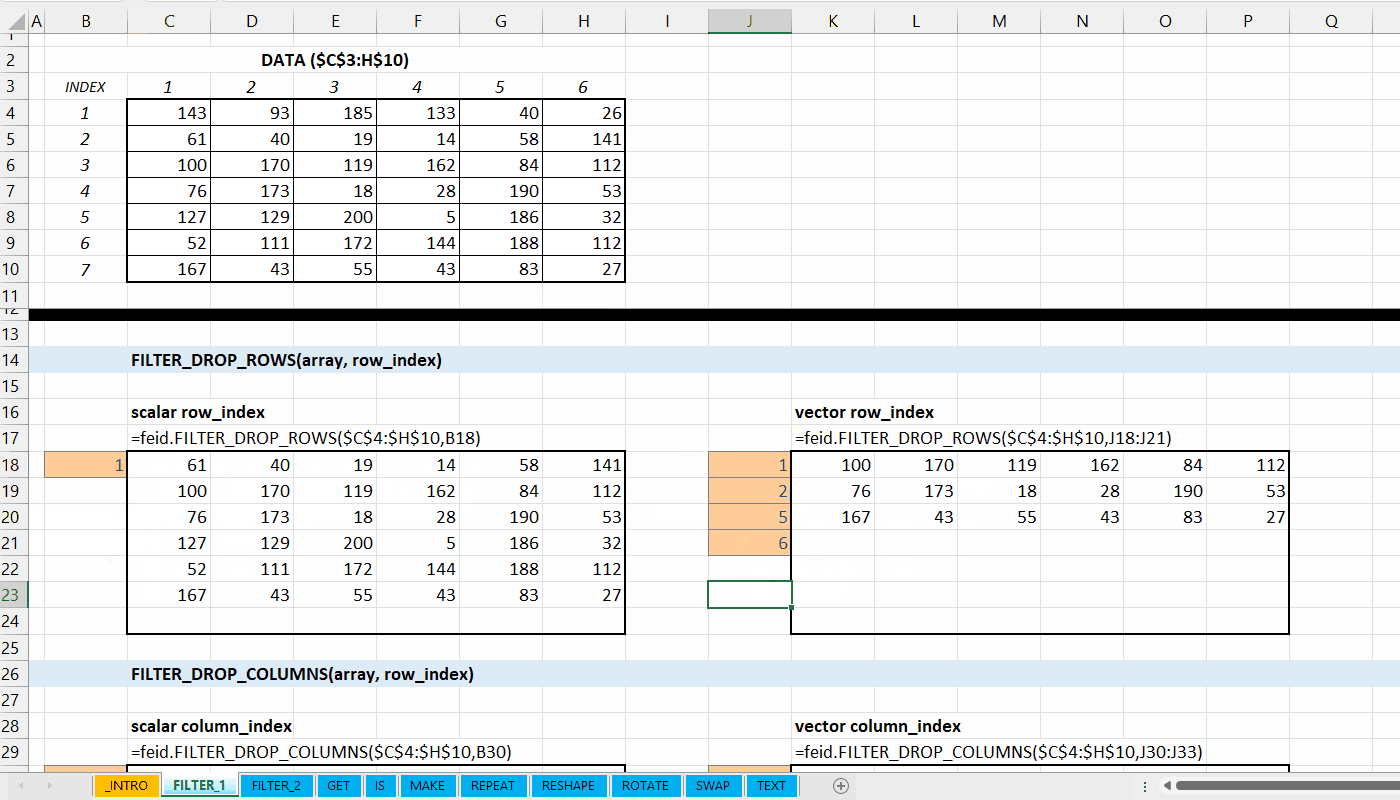
Fungsi FILTER_DROP_ROWS(array, row_index) digunakan untuk menghapus baris dari data.
Syntax
FILTER_DROP_ROWS(array, row_index)
Output
array
array := [array | vector]
Data berupa array atau vector yang memiliki baris lebih dari satu.
row_index := [integer number | integer vector]
Indeks baris yang ingin dihapus.
Gambar 3.2: Demonstrasi FILTER_DROP_ROWS()
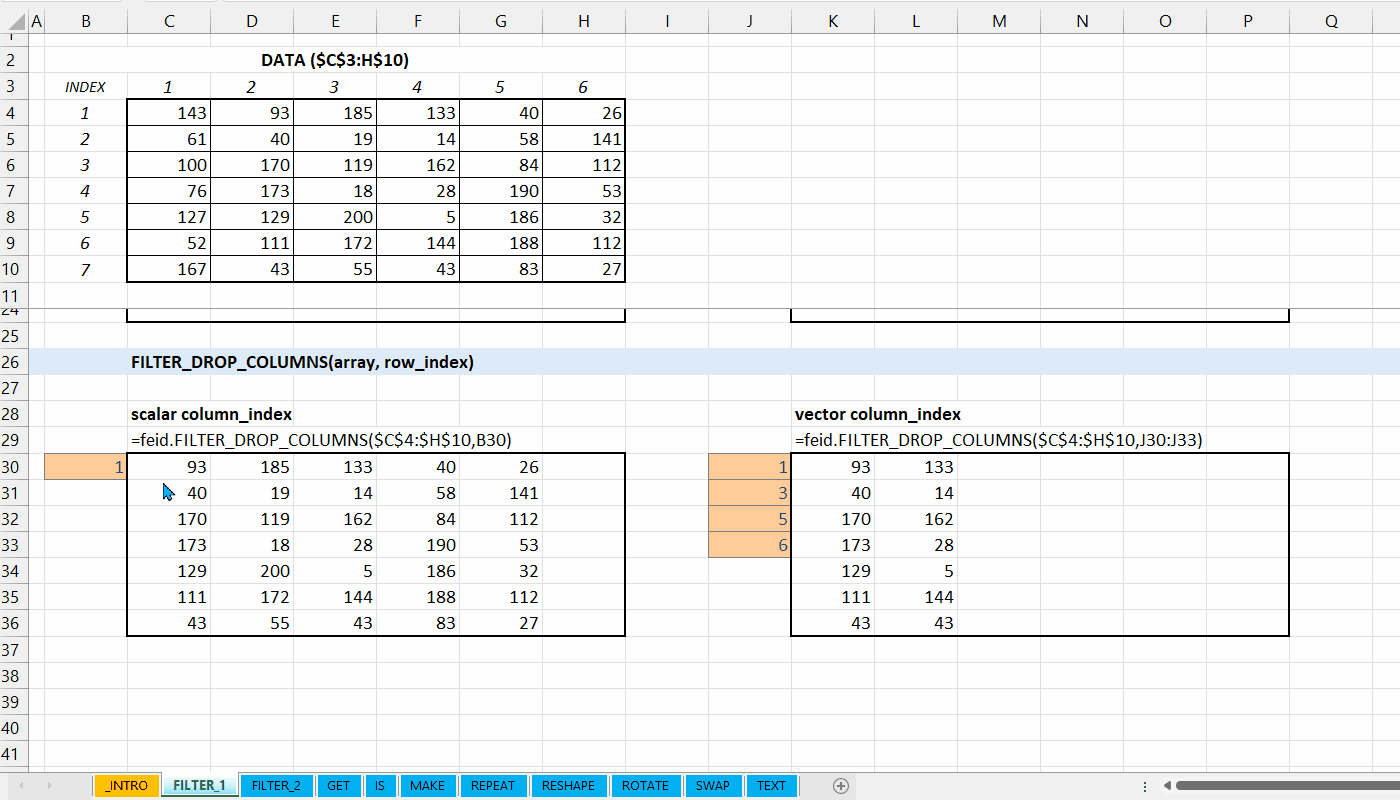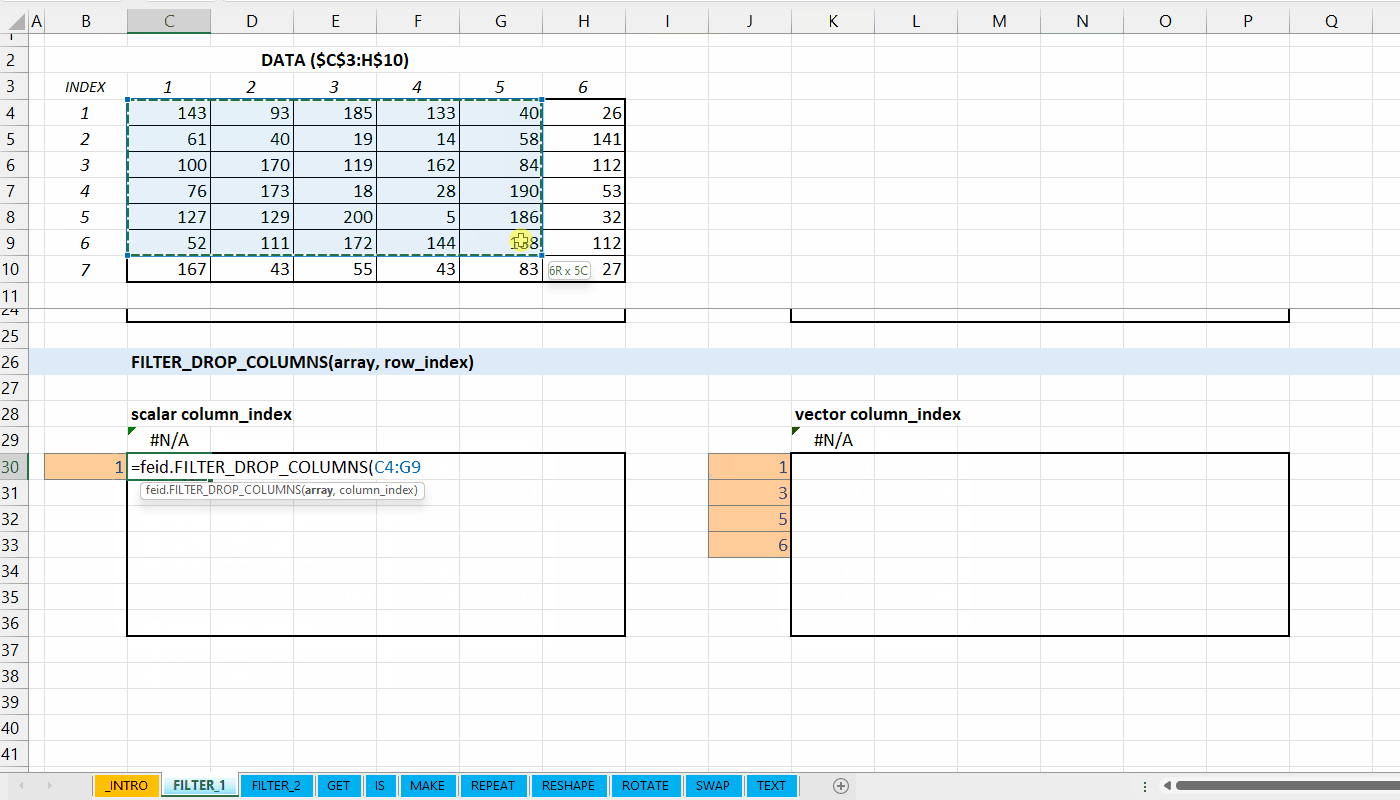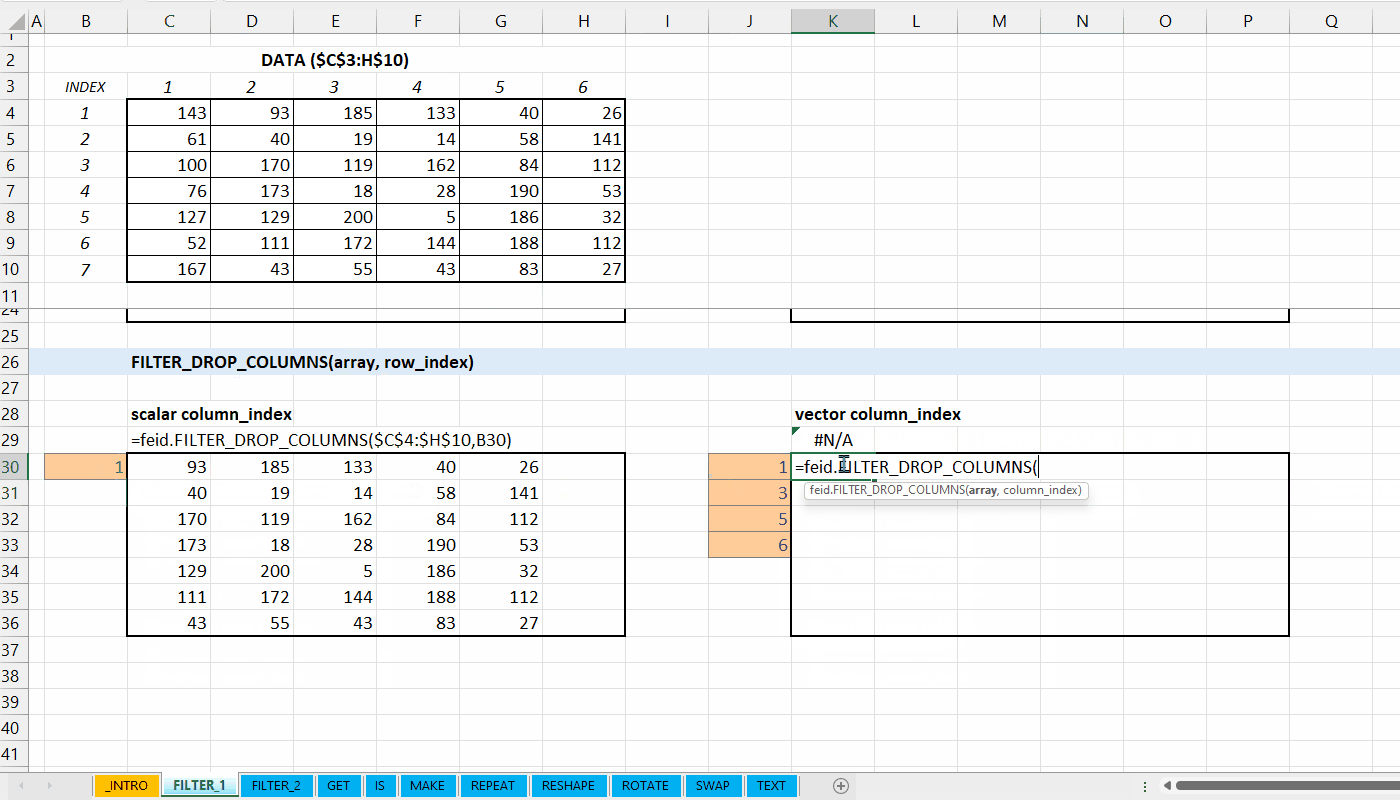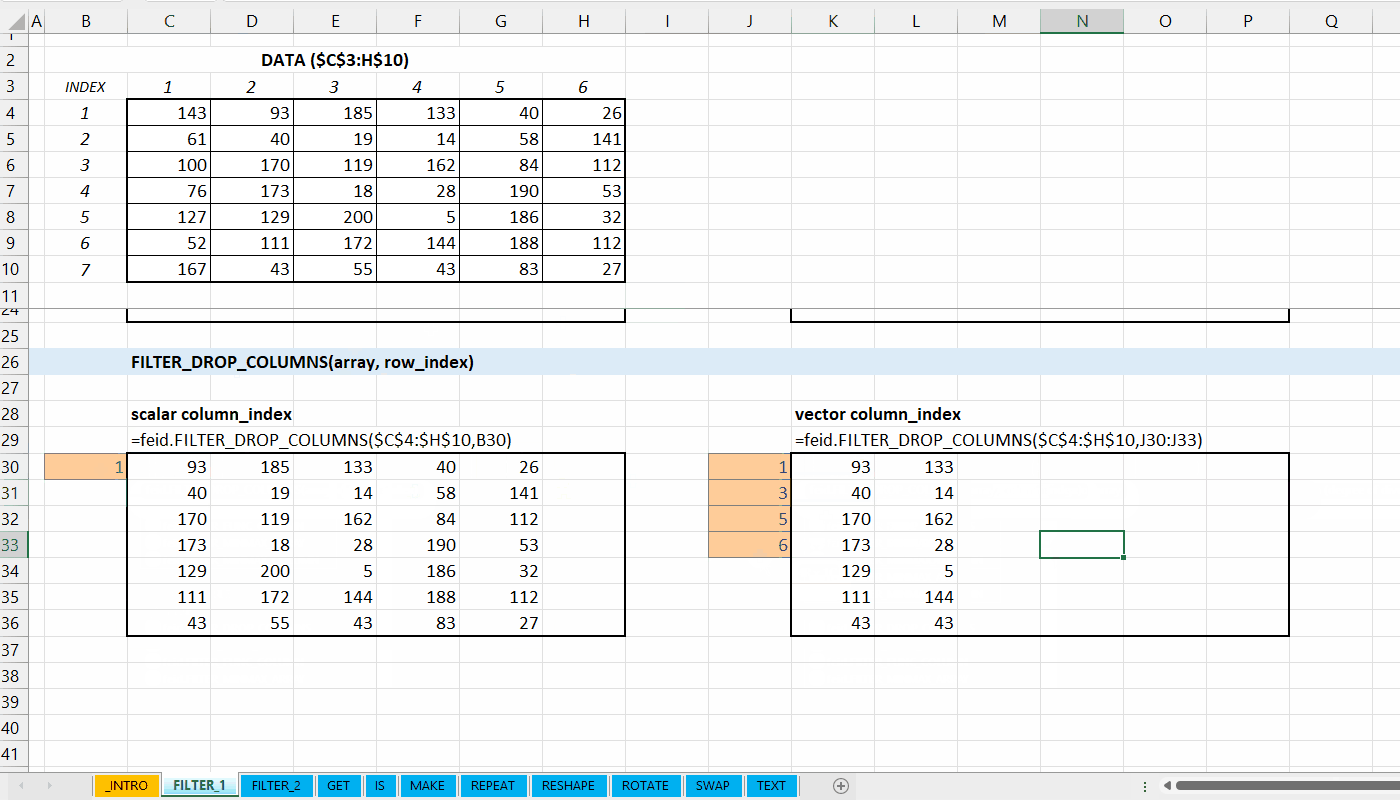
FILTER_DROP_COLUMNS()
Fungsi FILTER_DROP_COLUMNS(array, column_index) digunakan untuk menghapus kolom dari data.
Syntax
FILTER_DROP_COLUMNS(array, column_index)
Output
array
array := [array | vector]
Data berupa array atau vector yang memiliki kolom lebih dari satu.
column_index := [integer number | integer vector]
Indeks kolom yang ingin dihapus.
Gambar 3.3: Demonstrasi FILTER_DROP_COLUMNS()
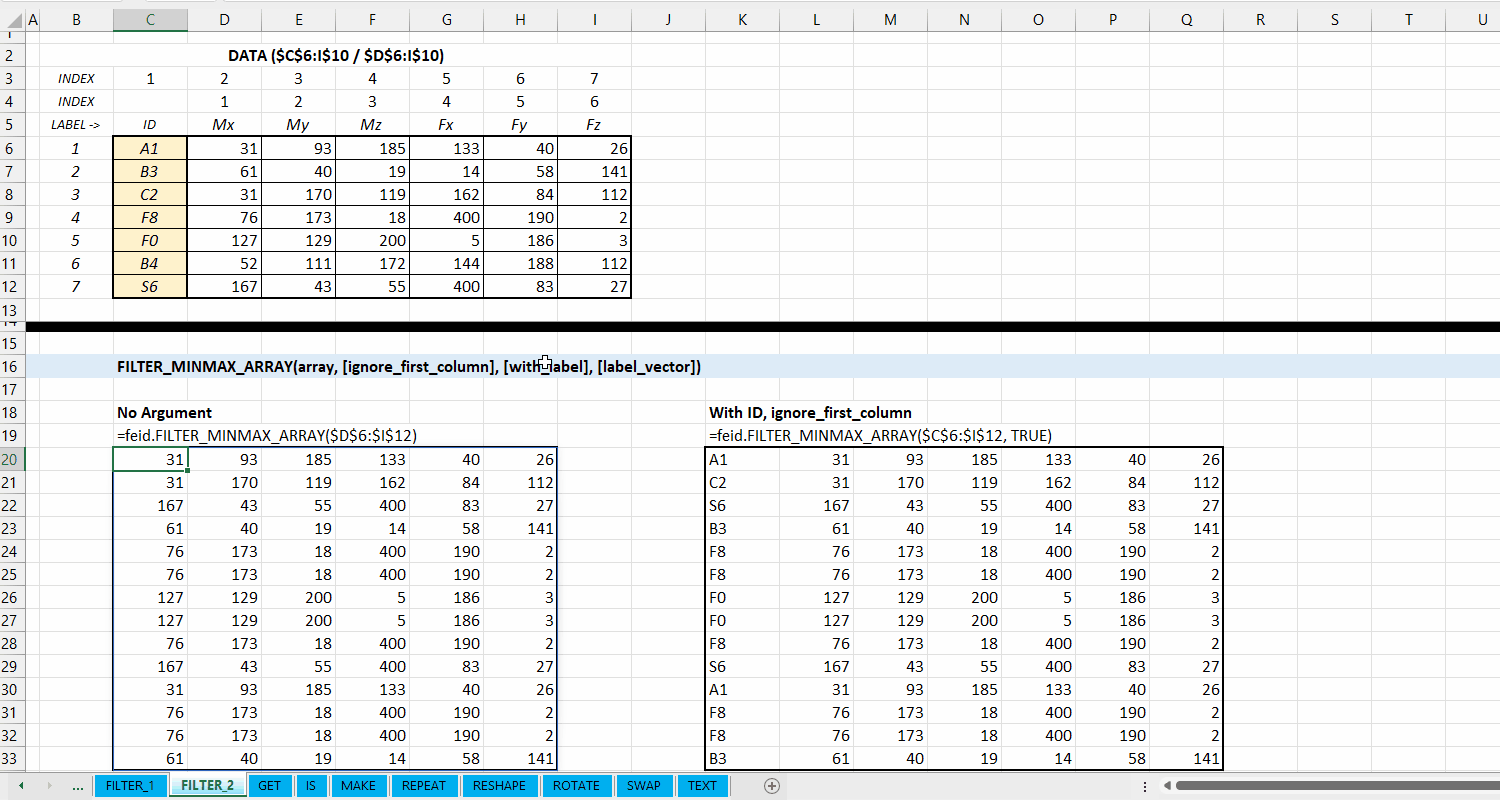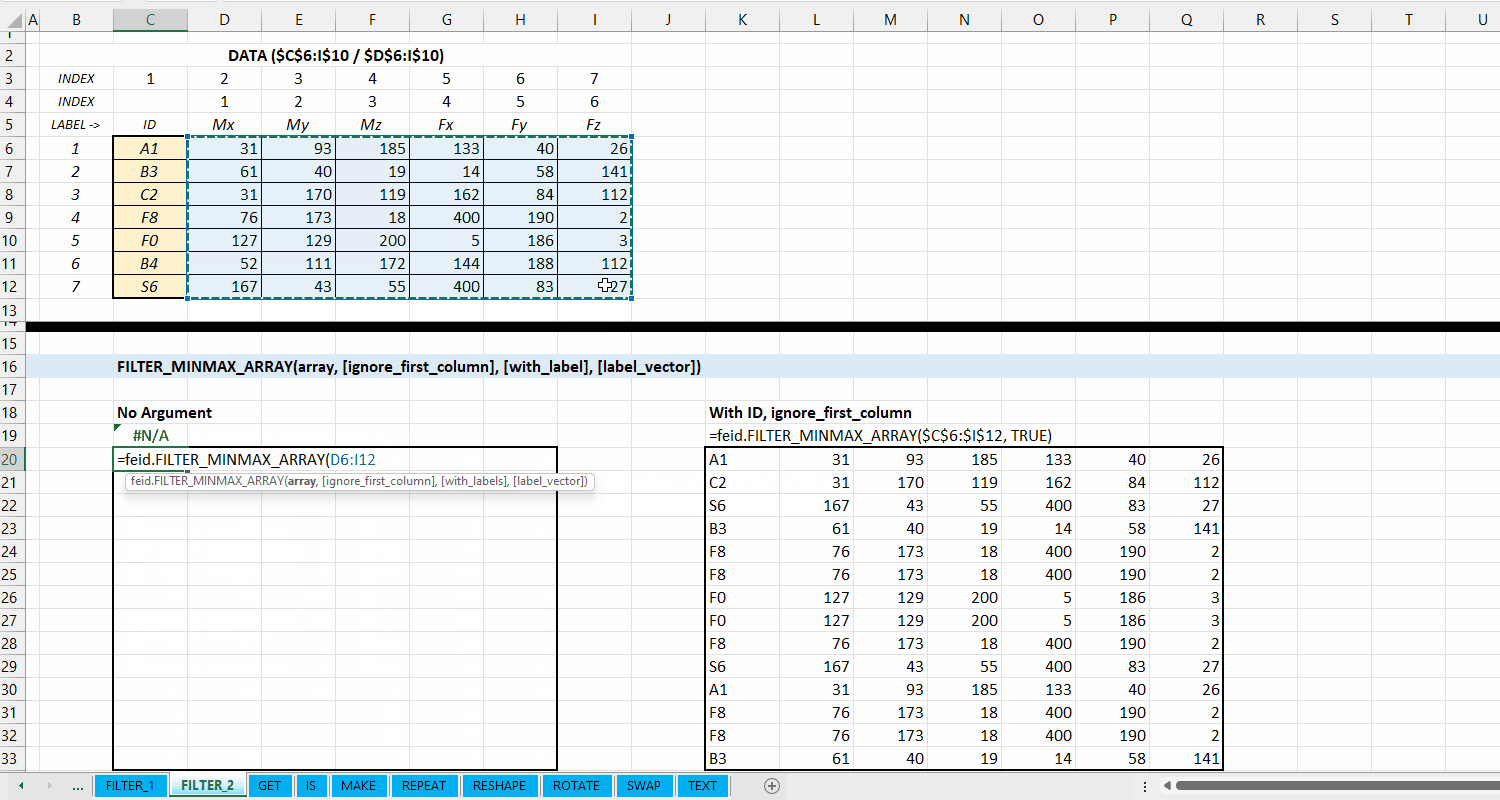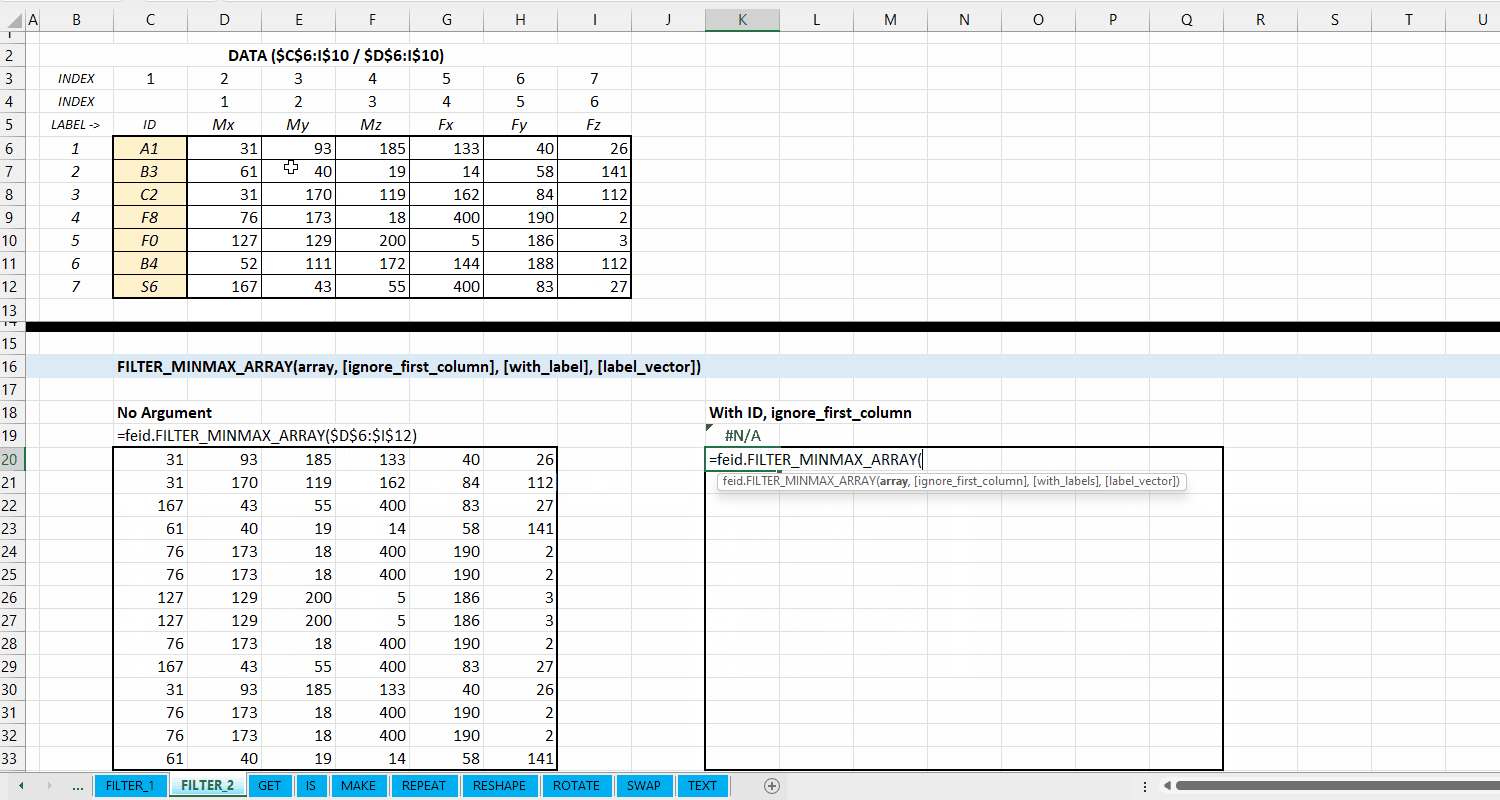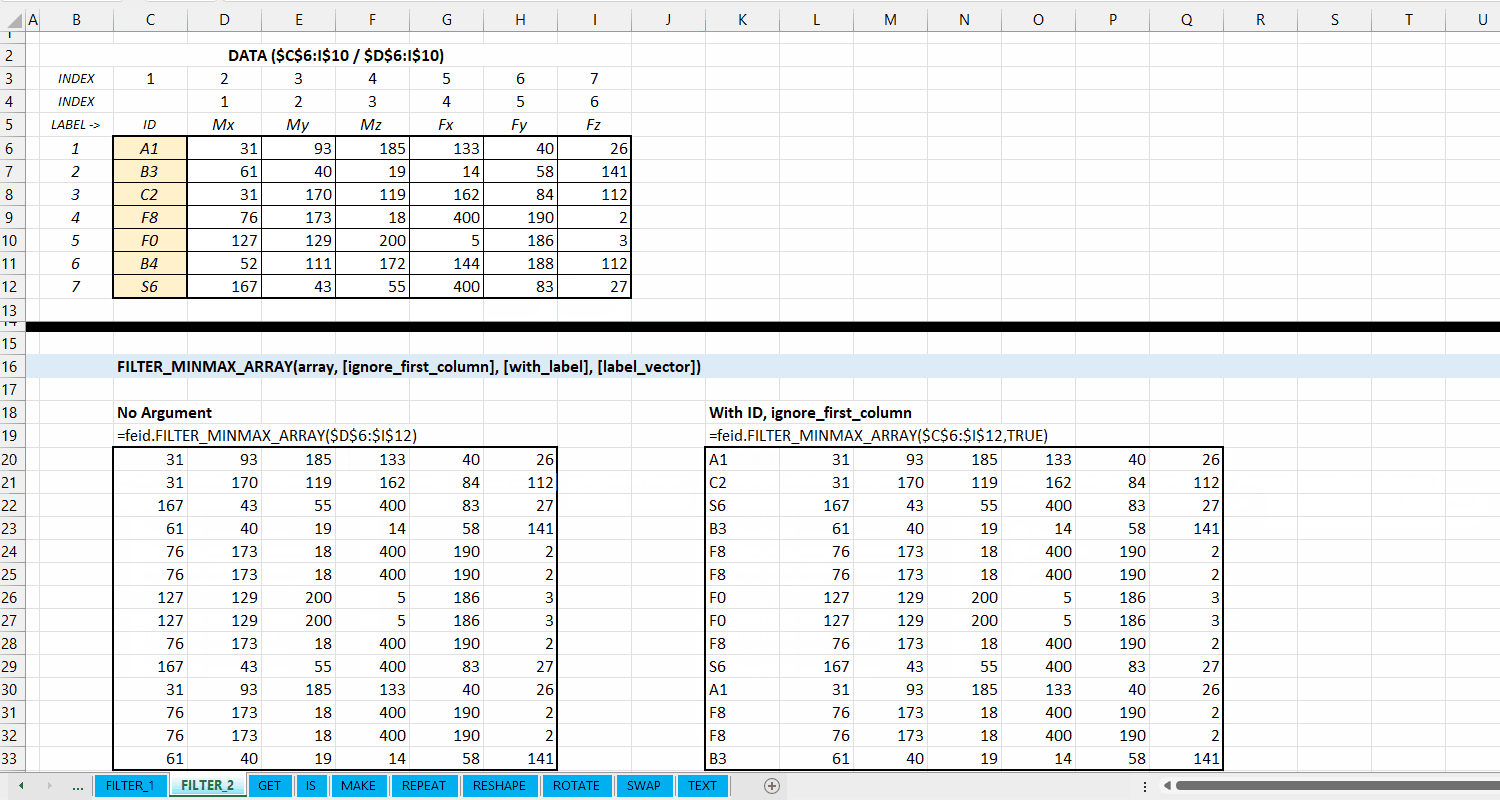
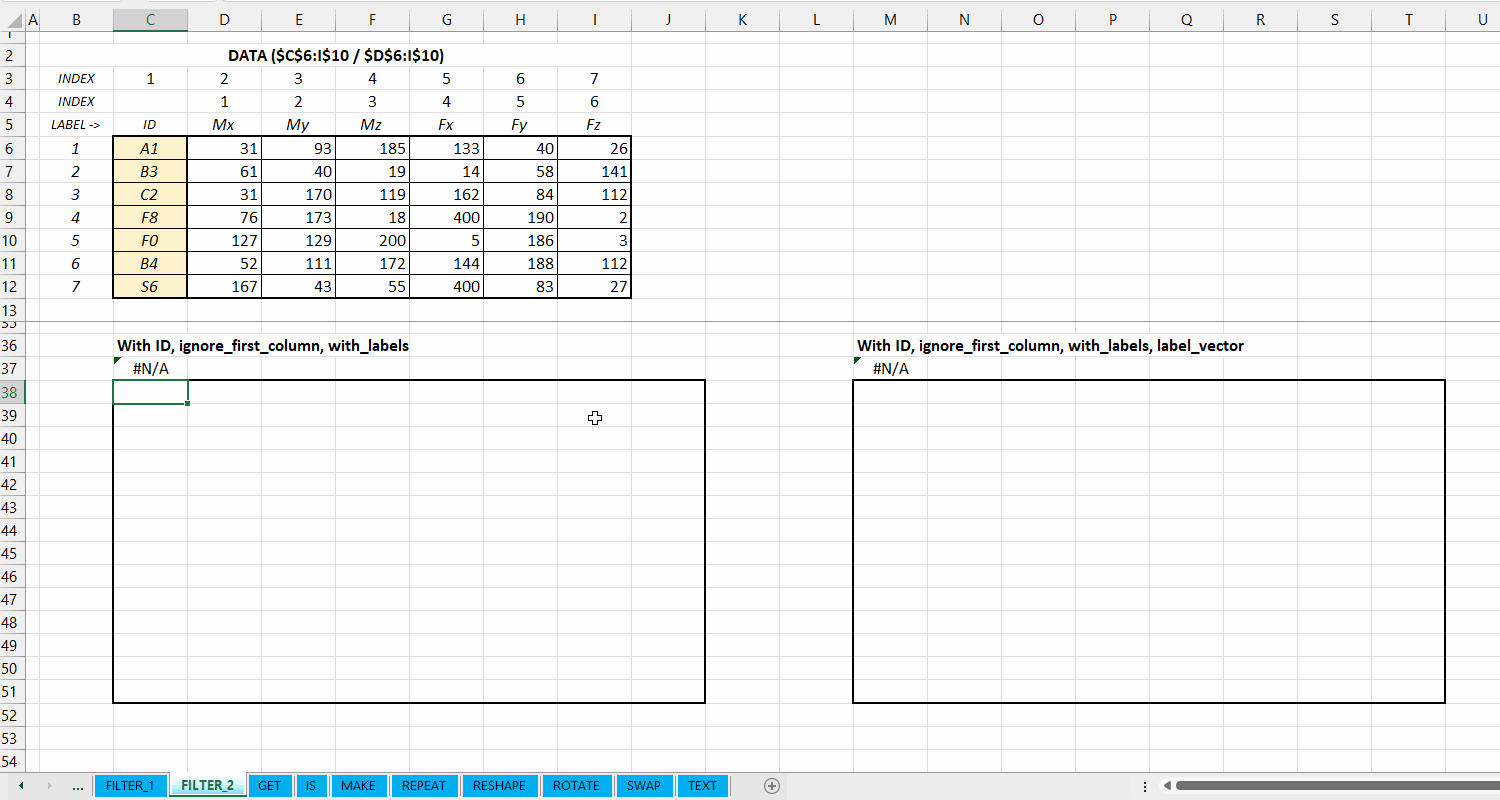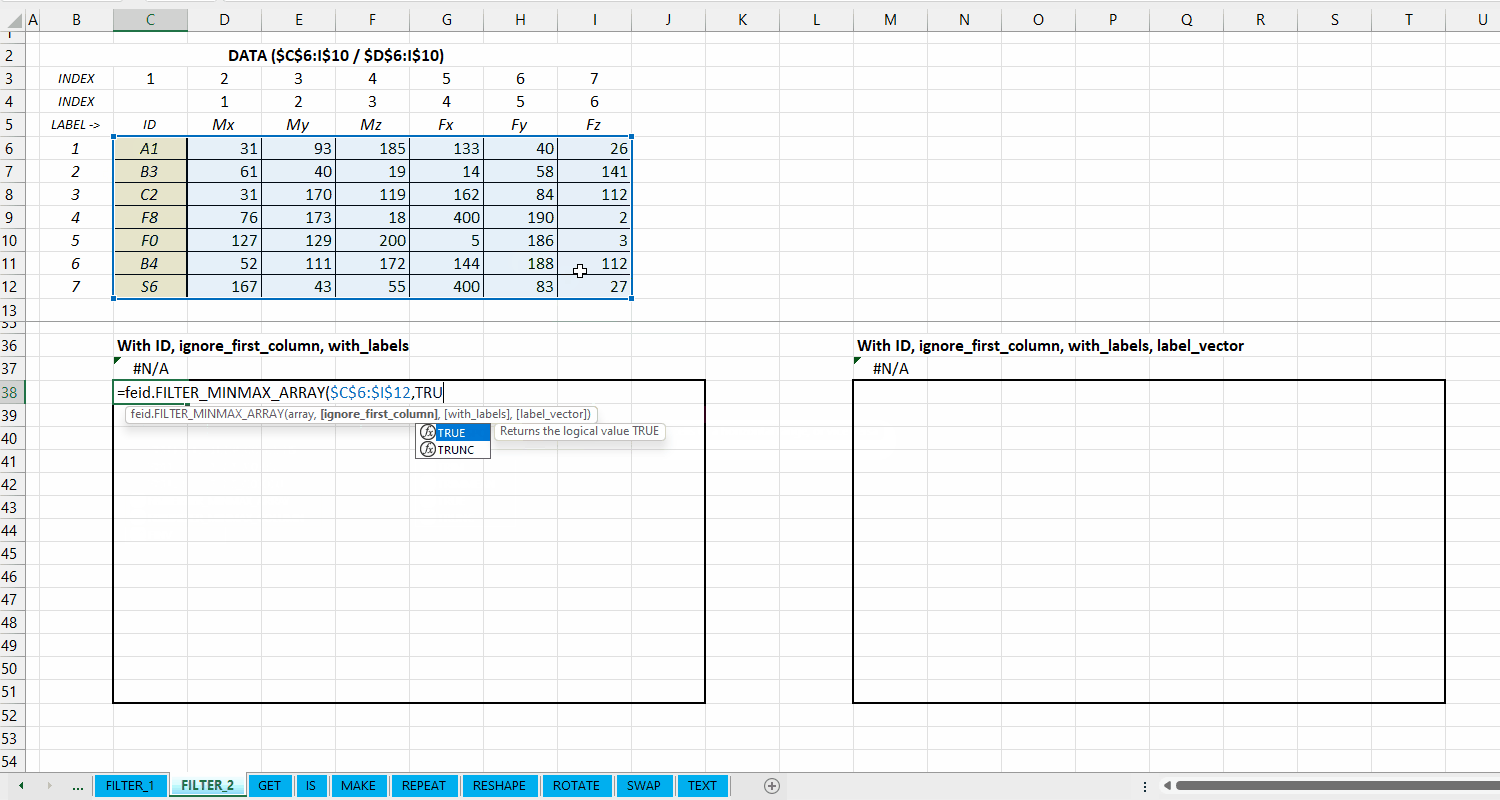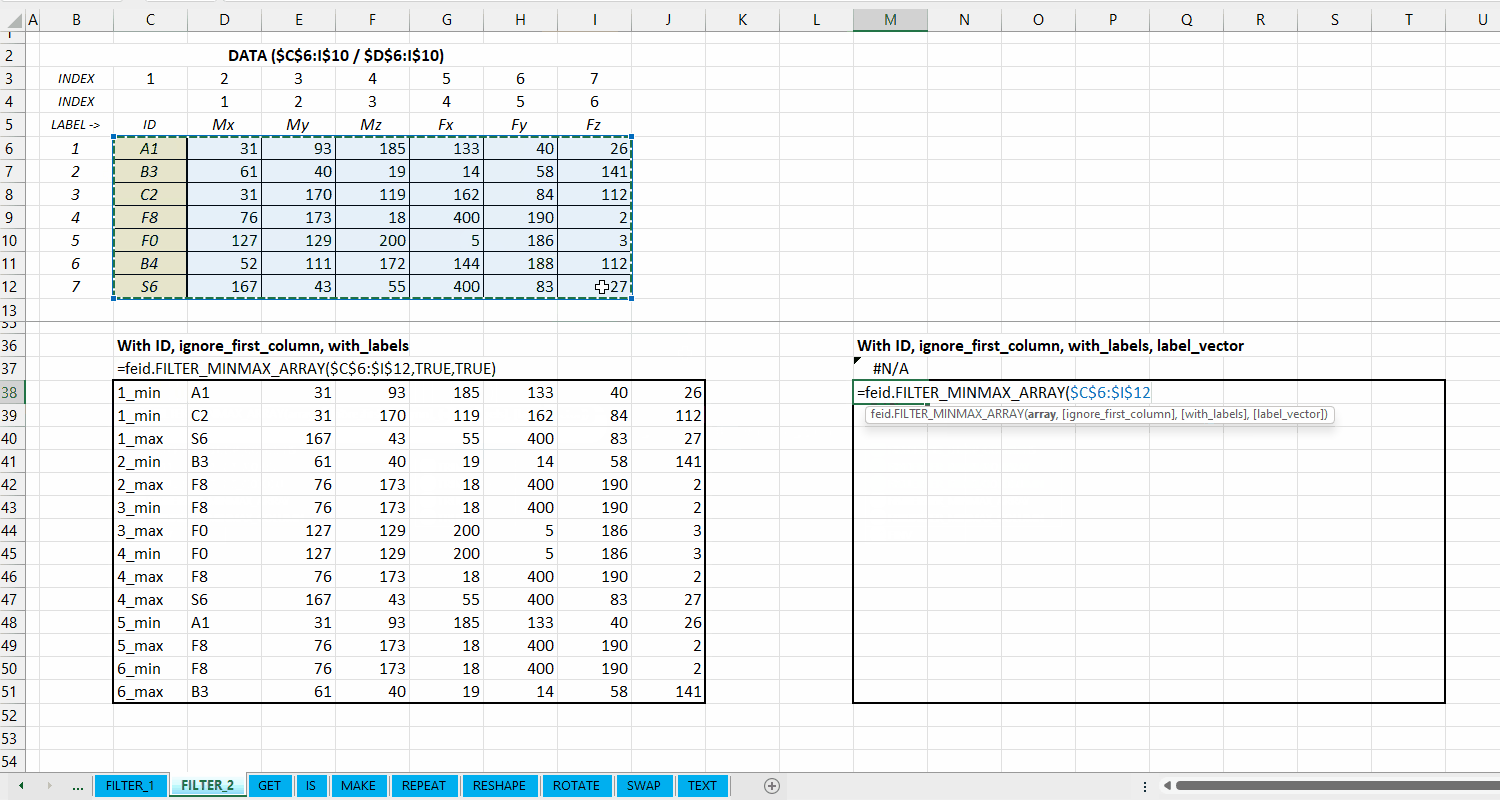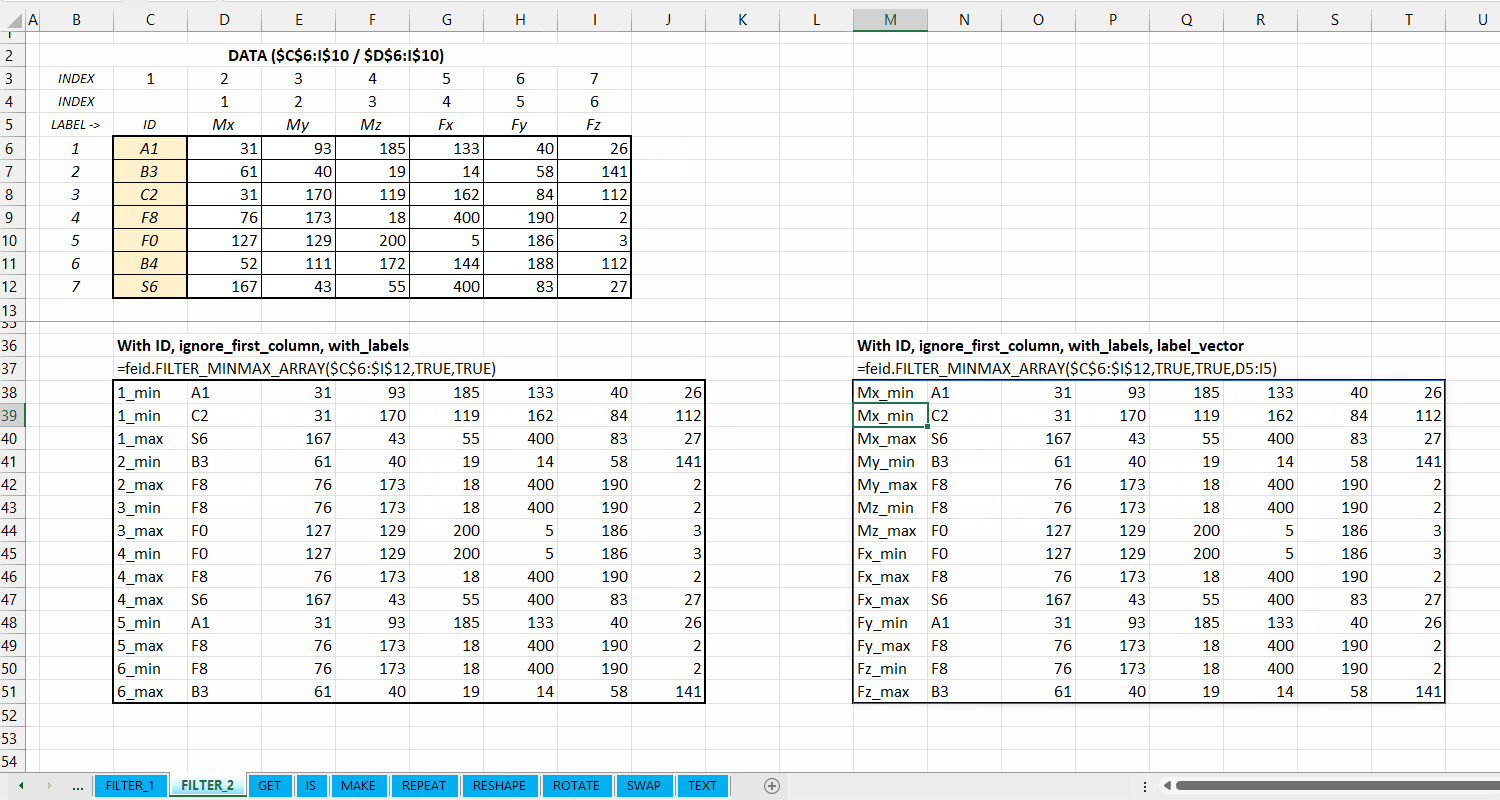
FILTER_MINMAX_ARRAY()
Fungsi FILTER_MINMAX_ARRAY(array, [ignore_first_column], [with_label], [label_vector], [take_first_only]) digunakan untuk melakukan filtering (memilah) data berdasarkan nilai minimum dan maksimum setiap kolomnya dan mengeluarkan hasil dalam berupa dynamic array.
Data berupa array dengan ketentuan array berisikan angka kecuali kolom pertama jika menggunakan opsi ignore_first_column.
[ignore_first_column] := FALSE :: [TRUE | FALSE]
Nilai default yaitu FALSE. Jika TRUE, maka kolom pertama dari array akan diabaikan dan tidak dilakukan filtering nilai minimum/maksimum.
[with_label] := FALSE :: [TRUE | FALSE]
Nilai default yaitu FALSE. Jika TRUE, maka kolom pertama dari output adalah label informasi minimum dan maksimum seperti 1_min, 1_max, atau no.column_min dan no.column_max. Untuk menggunakan label sendiri, masukin vector label di argumen label_vector.
[label_vector] := NONE :: [vector]
Nilai default yaitu NONE. Jika NONE, maka label setiap baris akan dinomori berdasarkan kolomnya (1_min, 1_max). Jika ingin menggunakan label dari nama kolom, jumlah elemen vector harus sama dengan jumlah kolom dari array. Untuk menggunakan label nilai with_label harus TRUE.
[take_first_only] := FALSE :: [TRUE | FALSE]
(New in v0.3.1). Nilai default yaitu FALSE. Jika TRUE, maka hanya baris pertama yang diambil dari hasil pencarian nilai minimum/maksimum.
Gambar 3.4: Demonstrasi FILTER_MINMAX_ARRAY()
Kategori GET_*
Kategori GET_* merupakan kumpulan fungsi yang digunakan untuk mengambil informasi dari suatu data. Hubungan antar fungsi di kategori ini bisa dilihat di Gambar 4.1.
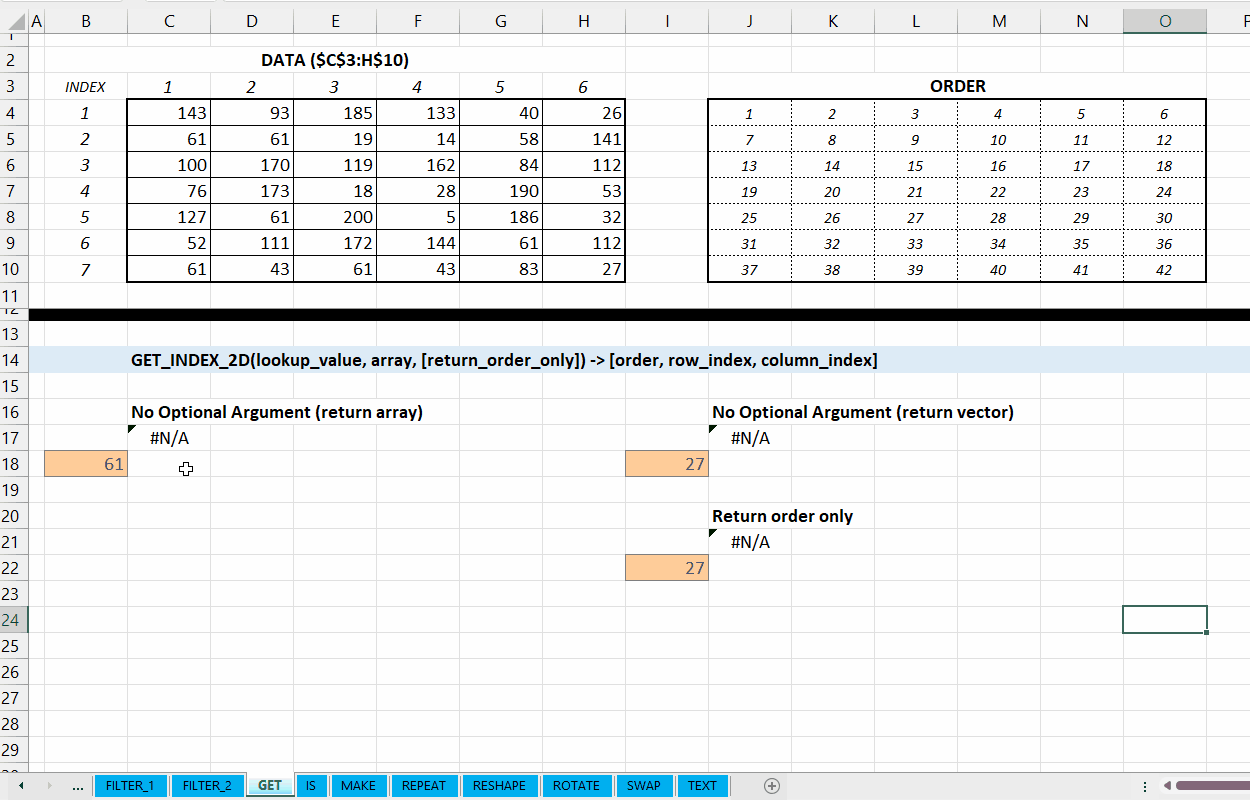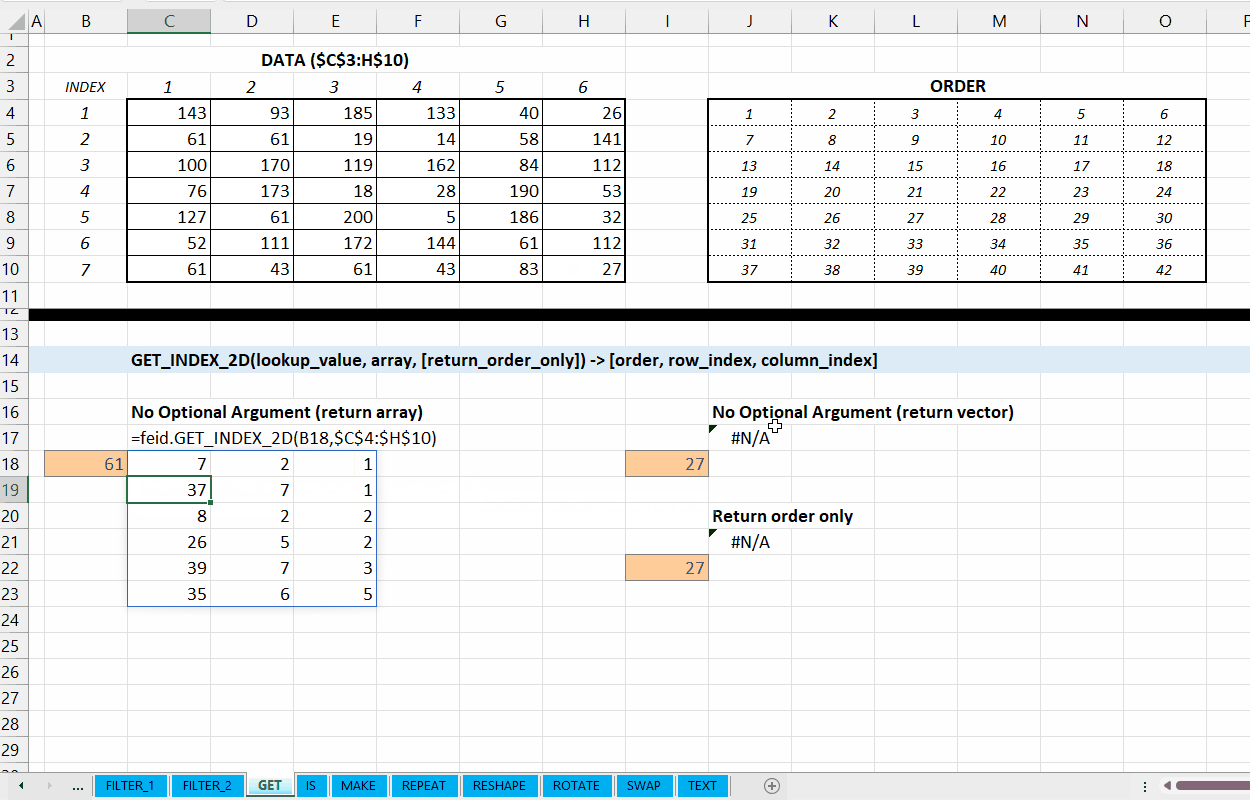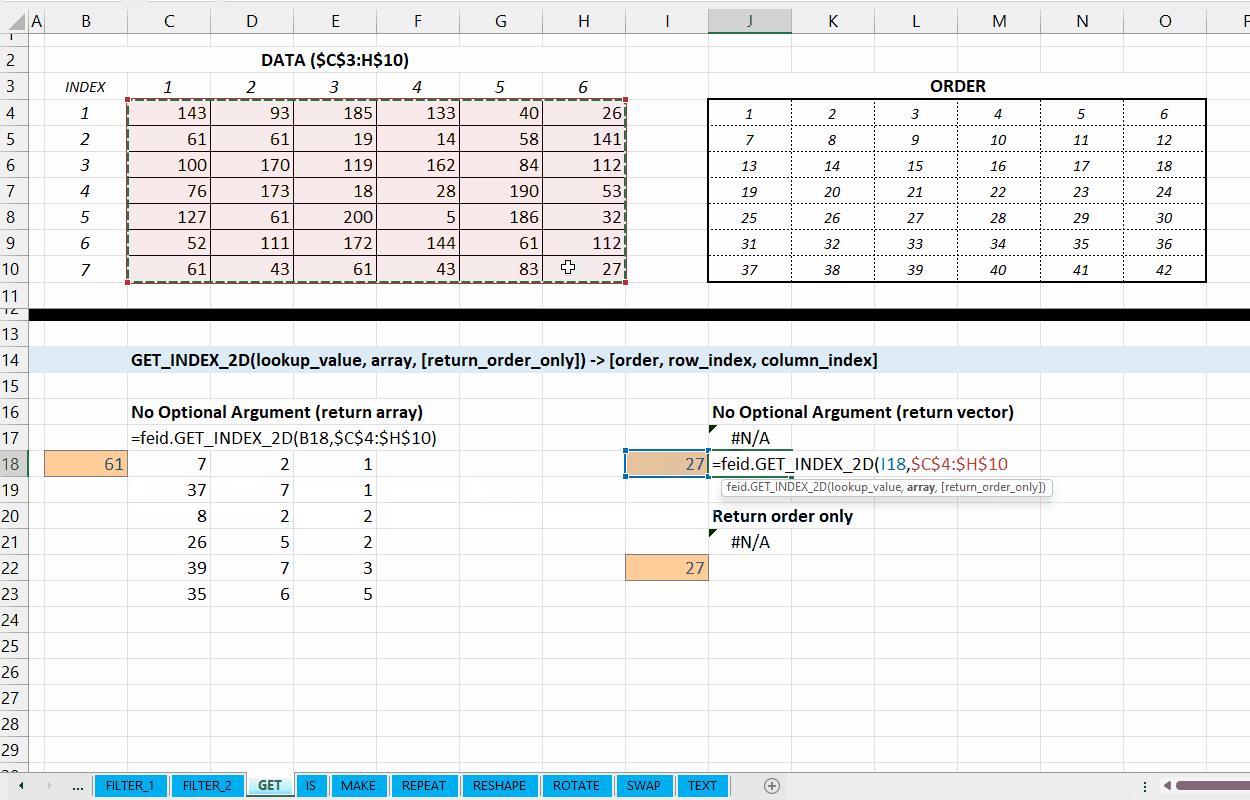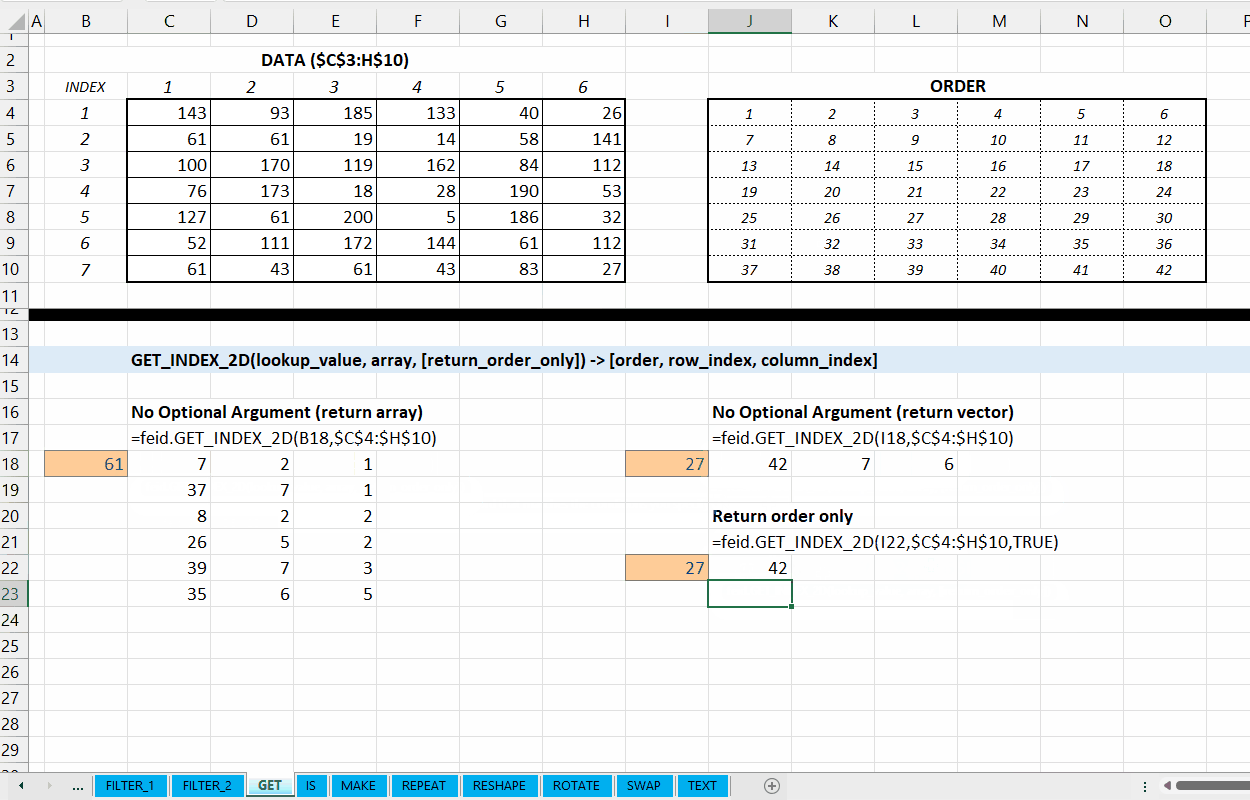
Fungsi GET_INDEX_2D(lookup_value, array, [return_as_order]) dapat digunakan untuk mengambil informasi urutan nilai yang dicari ataupun posisi baris/kolom dari array.
array ([order, row index, column index]) atau number vector (order)
lookup_value := [scalar]
Nilai yang dicari dalam array. Nilai lookup_value adalah nilai tunggal berupa scalar.
array := [array]
Data berupa array.
[return_as_order] := FALSE :: [TRUE | FALSE]
Nilai default yaitu FALSE. Jika TRUE, hasil fungsi memberikan urutan angka nilai yang dicari. Urutan dimulai dari horizontal kiri teratas sampai kanan terbawah. Jika FALSE, maka output terdiri dari nomor urut, indeks kolom, dan indeks baris.
Gambar 4.2: Demonstrasi GET_INDEX_2D()
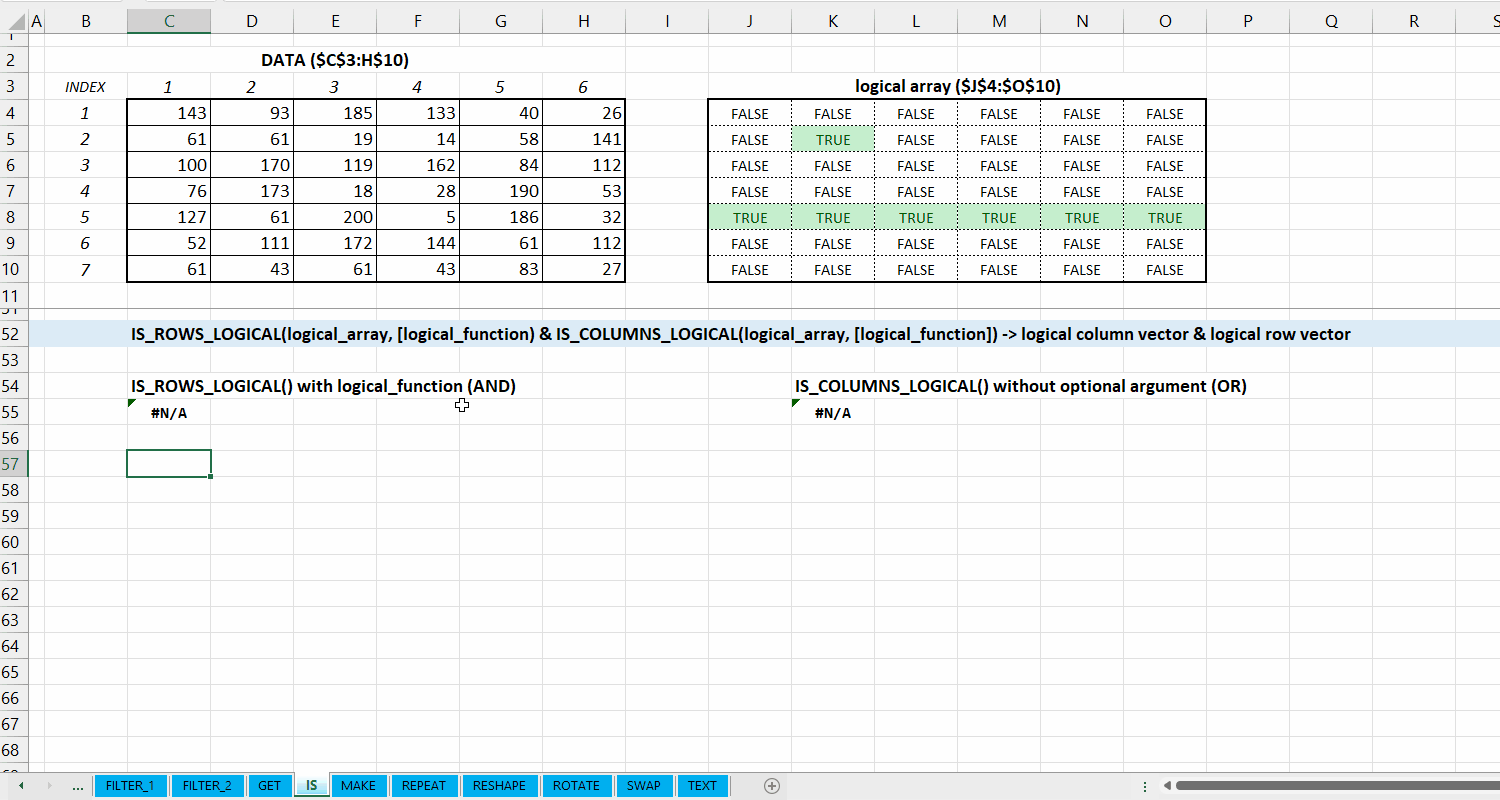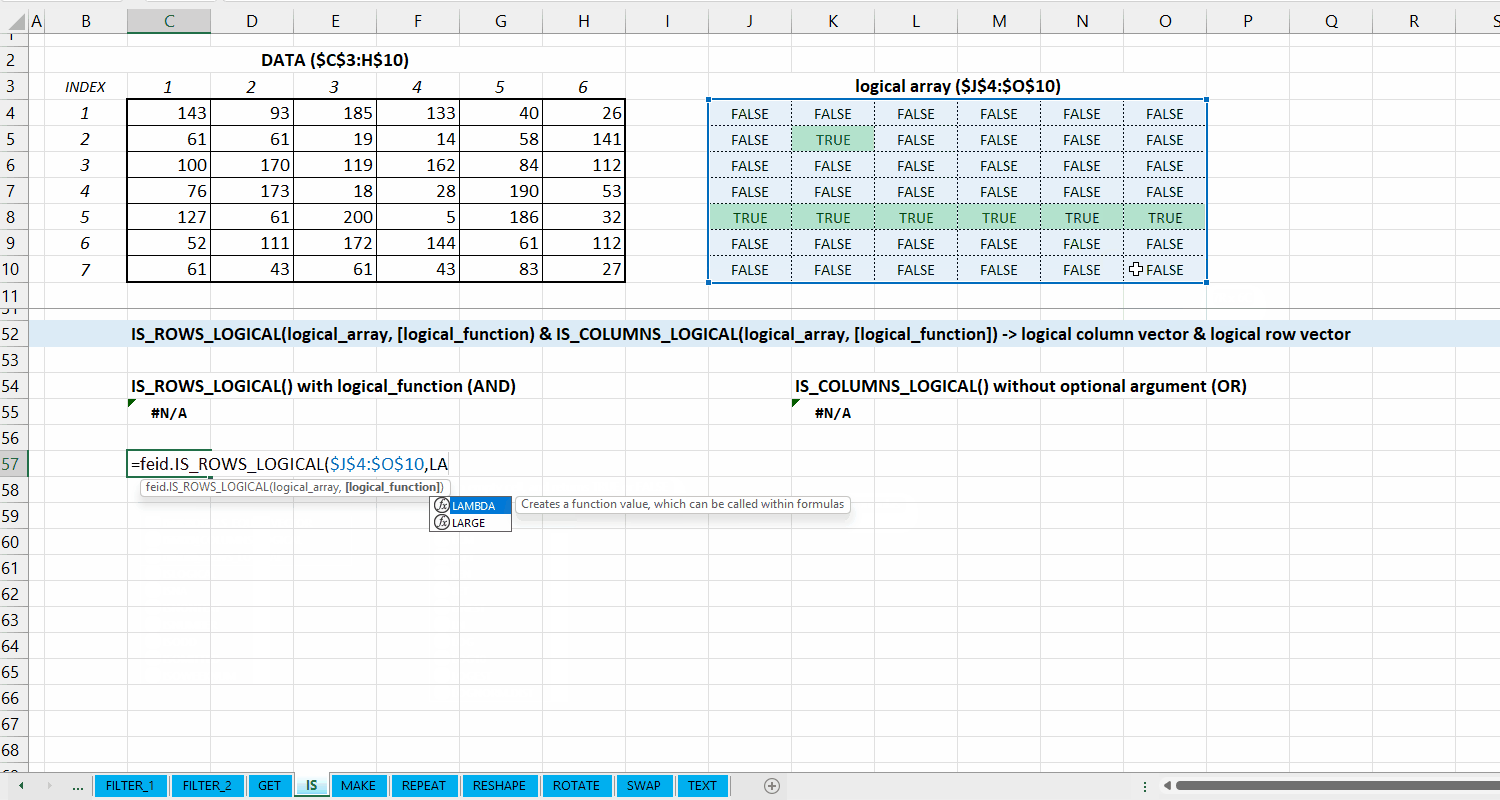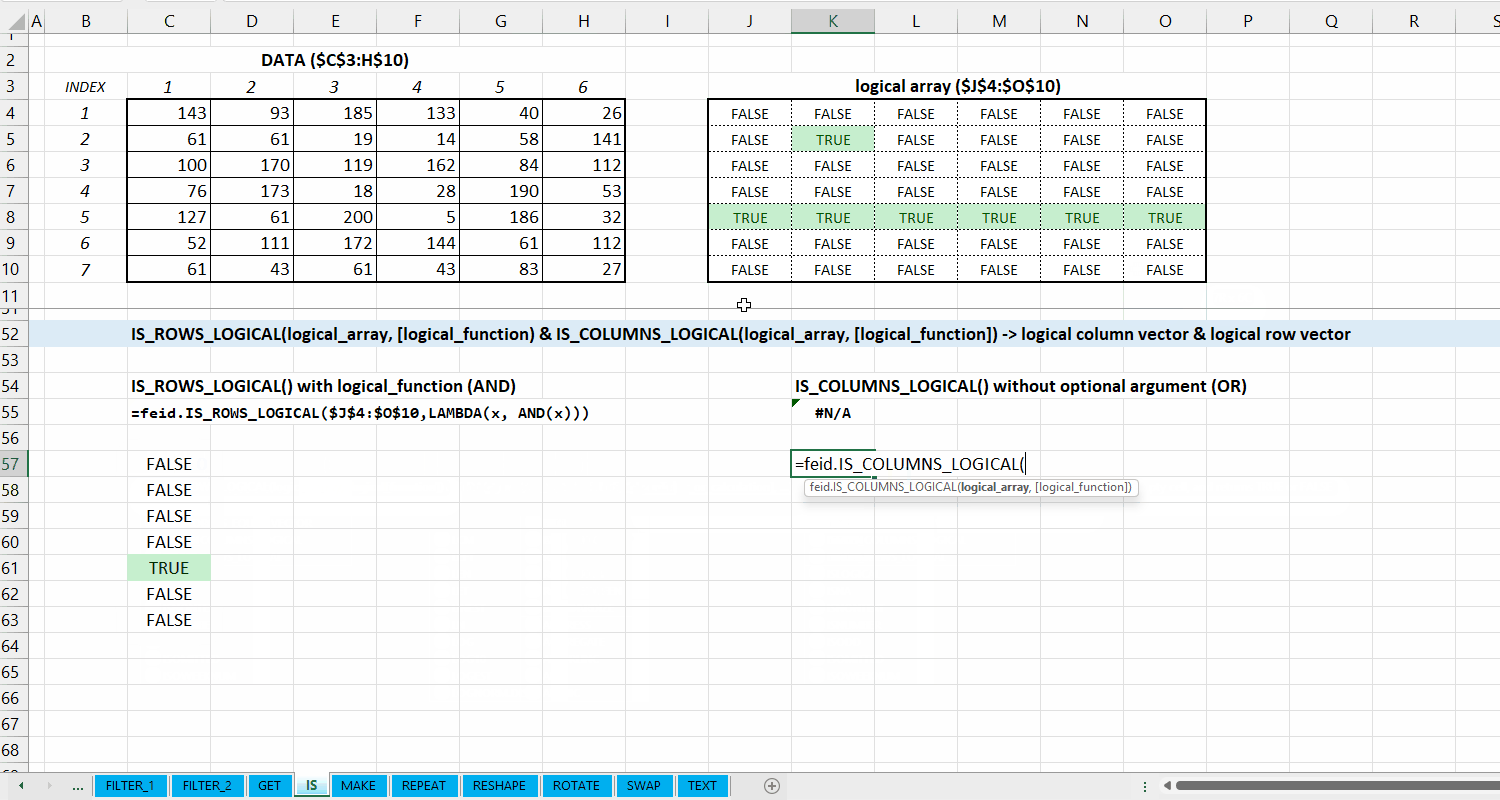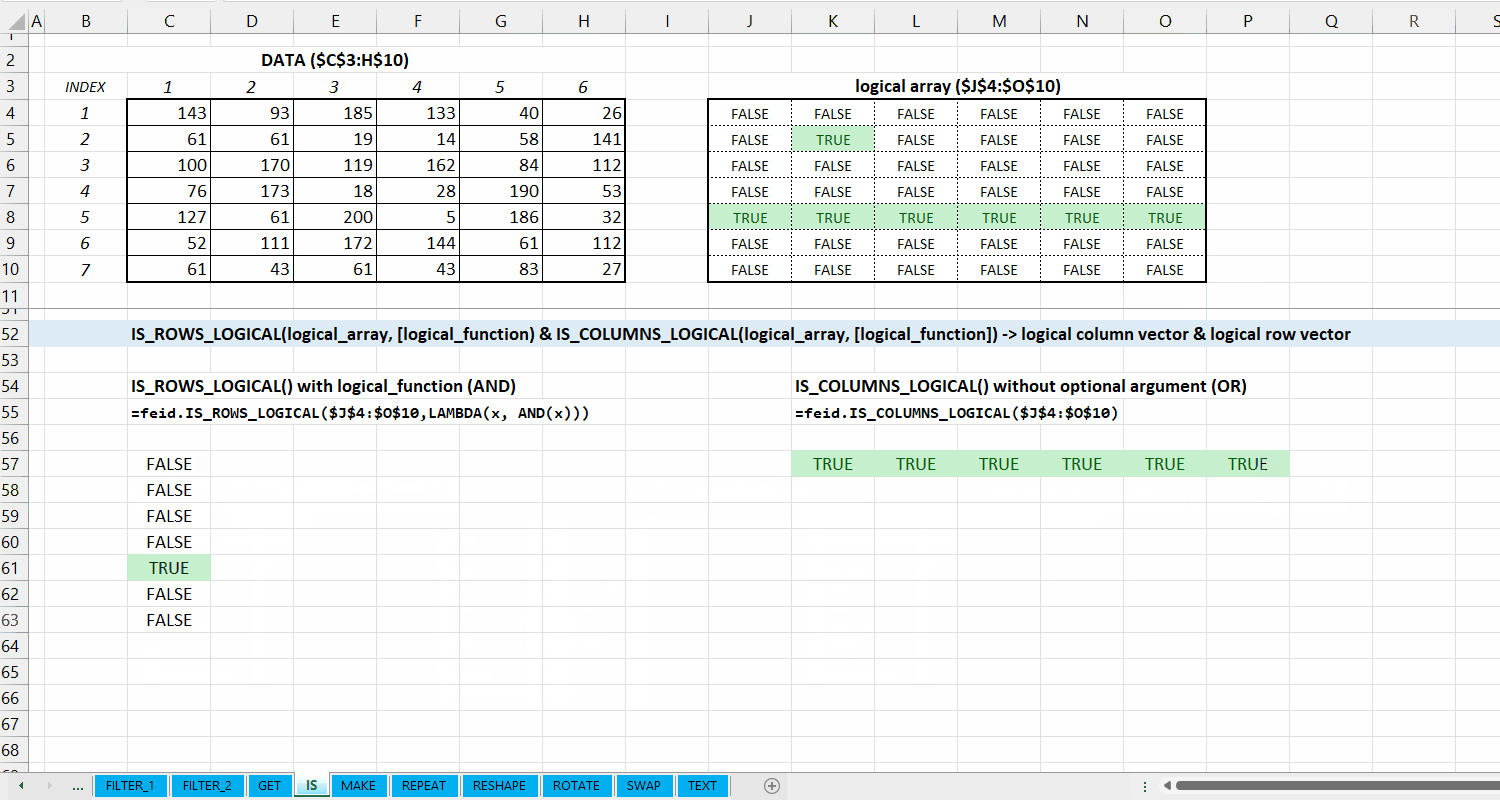
Kategori IS_*
Kategori IS_* merupakan kumpulan fungsi yang dapat digunakan untuk melakukan fungsi logical di data. Hubungan antar fungsi di kategori ini bisa dilihat di Gambar 5.1.
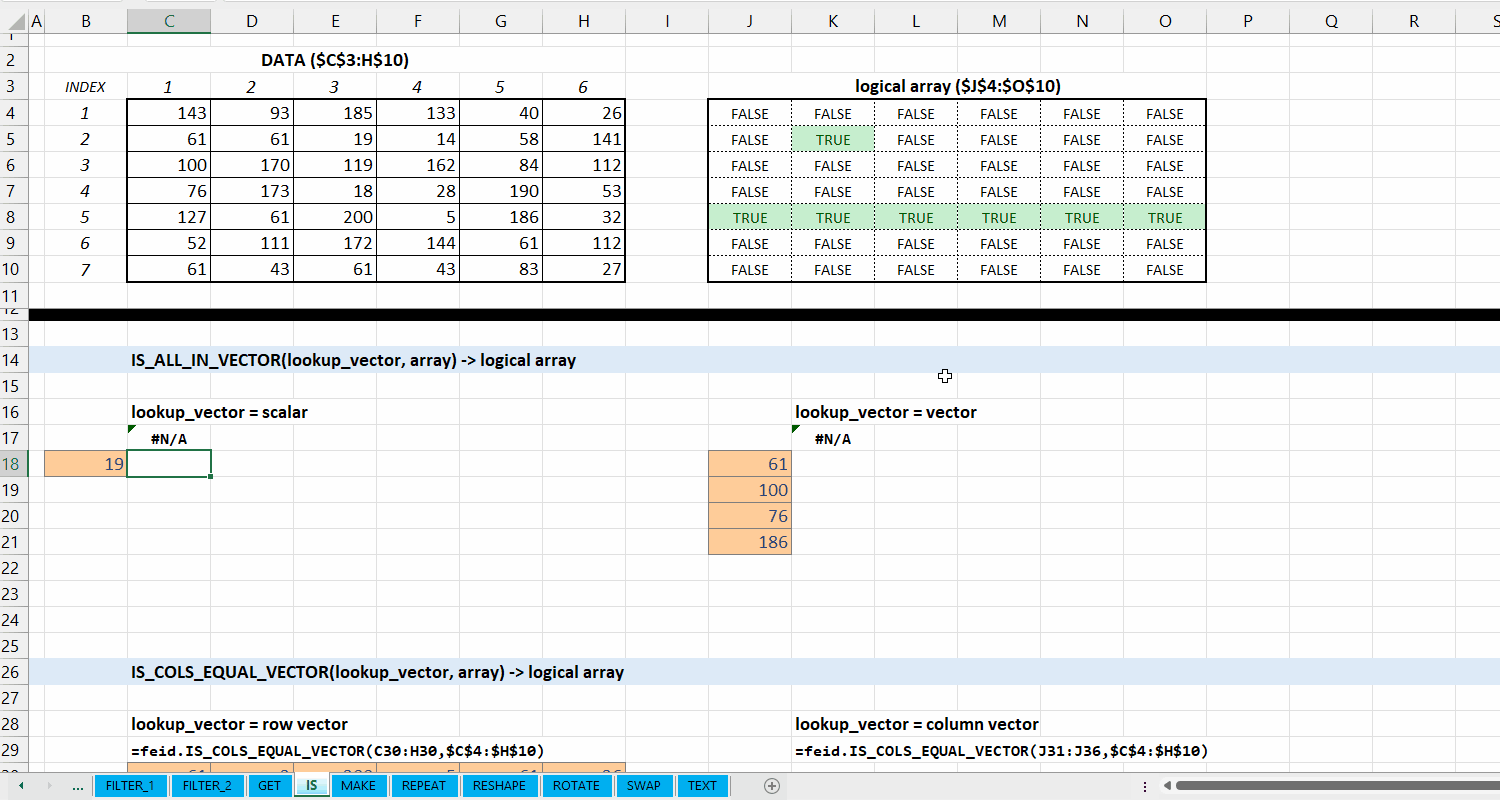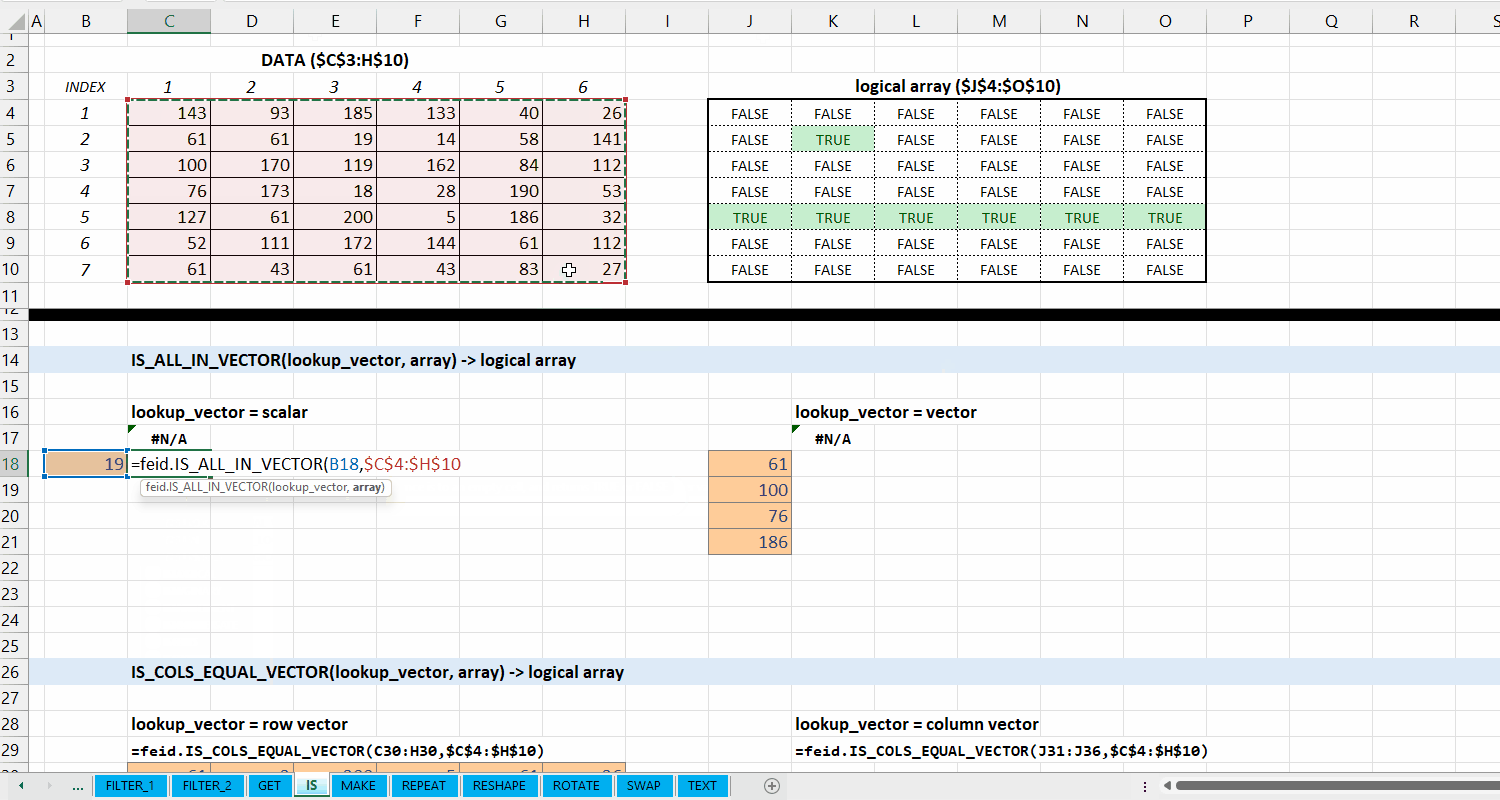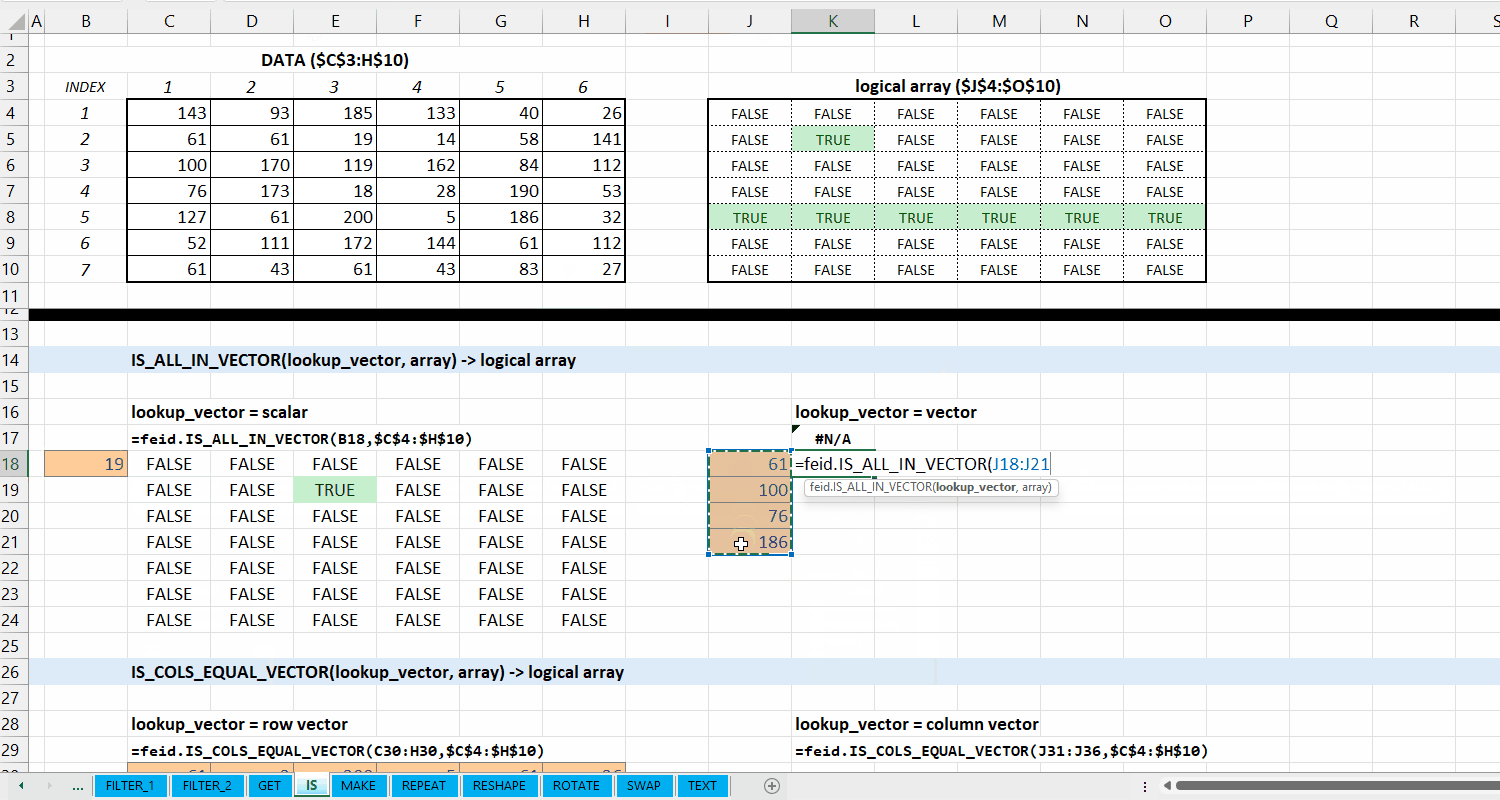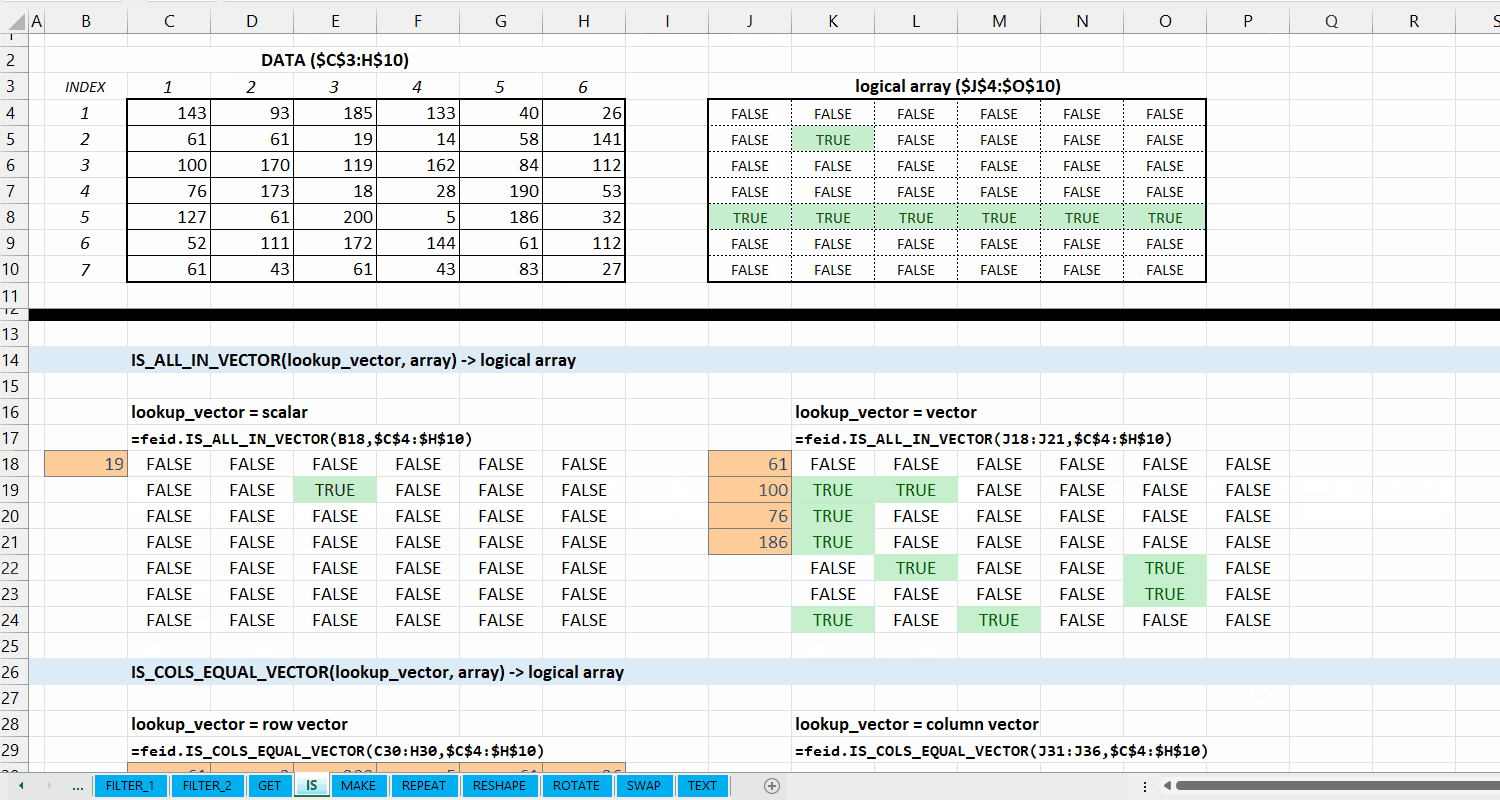
Fungsi IS_ALL_IN_VECTOR(lookup_vector, array) digunakan untuk memeriksa apakah setiap elemen di array termasuk dari lookup_vector.
Syntax
IS_ALL_IN_VECTOR(lookup_vector, array)
Output
logical array
lookup_vector := [scalar | vector]
Vector yang terdiri dari nilai yang ingin dicocokkan.
array := [array | vector]
Data berupa array atau vector.
Gambar 5.2: Demonstrasi IS_ALL_IN_VECTOR()
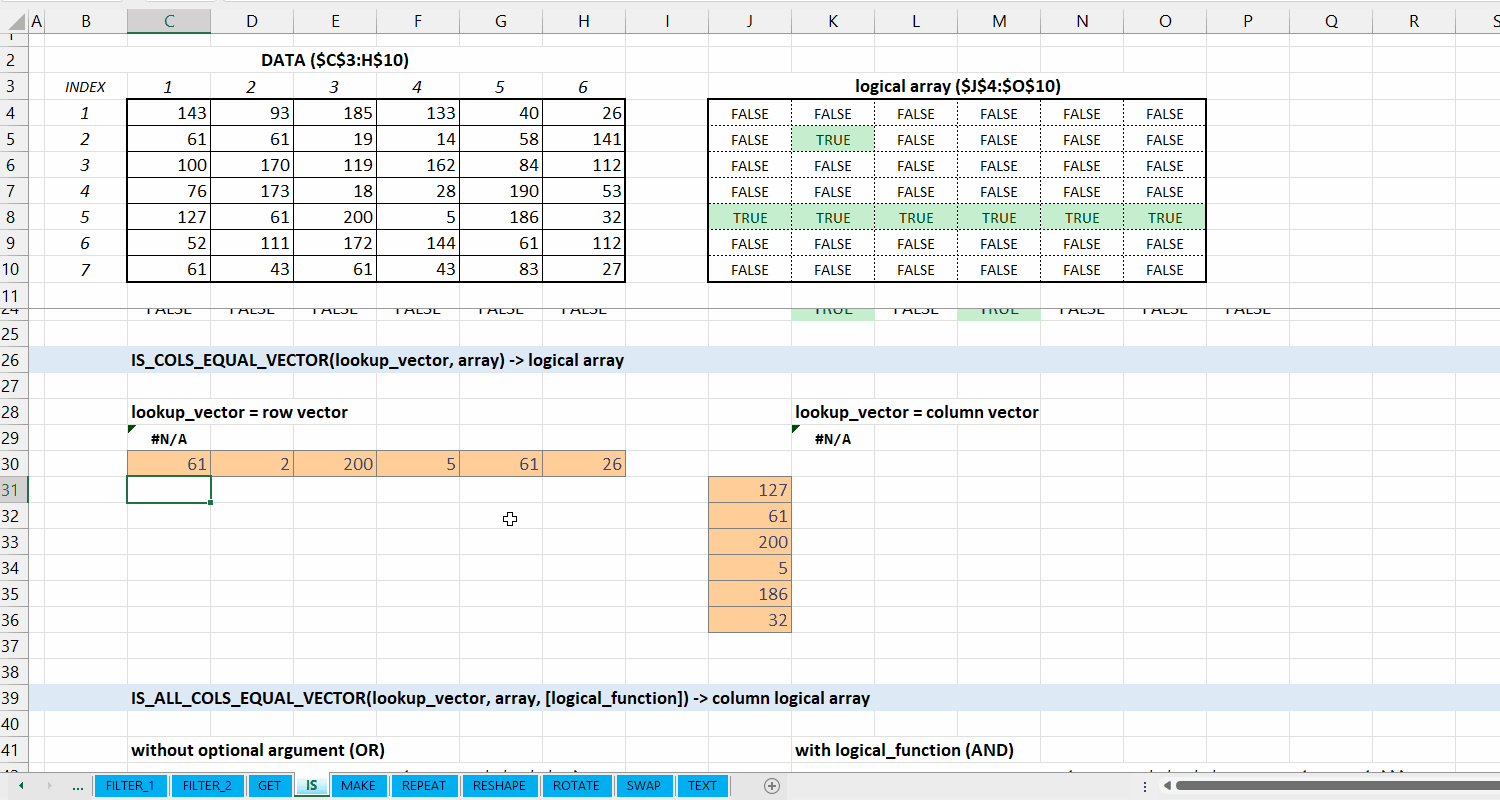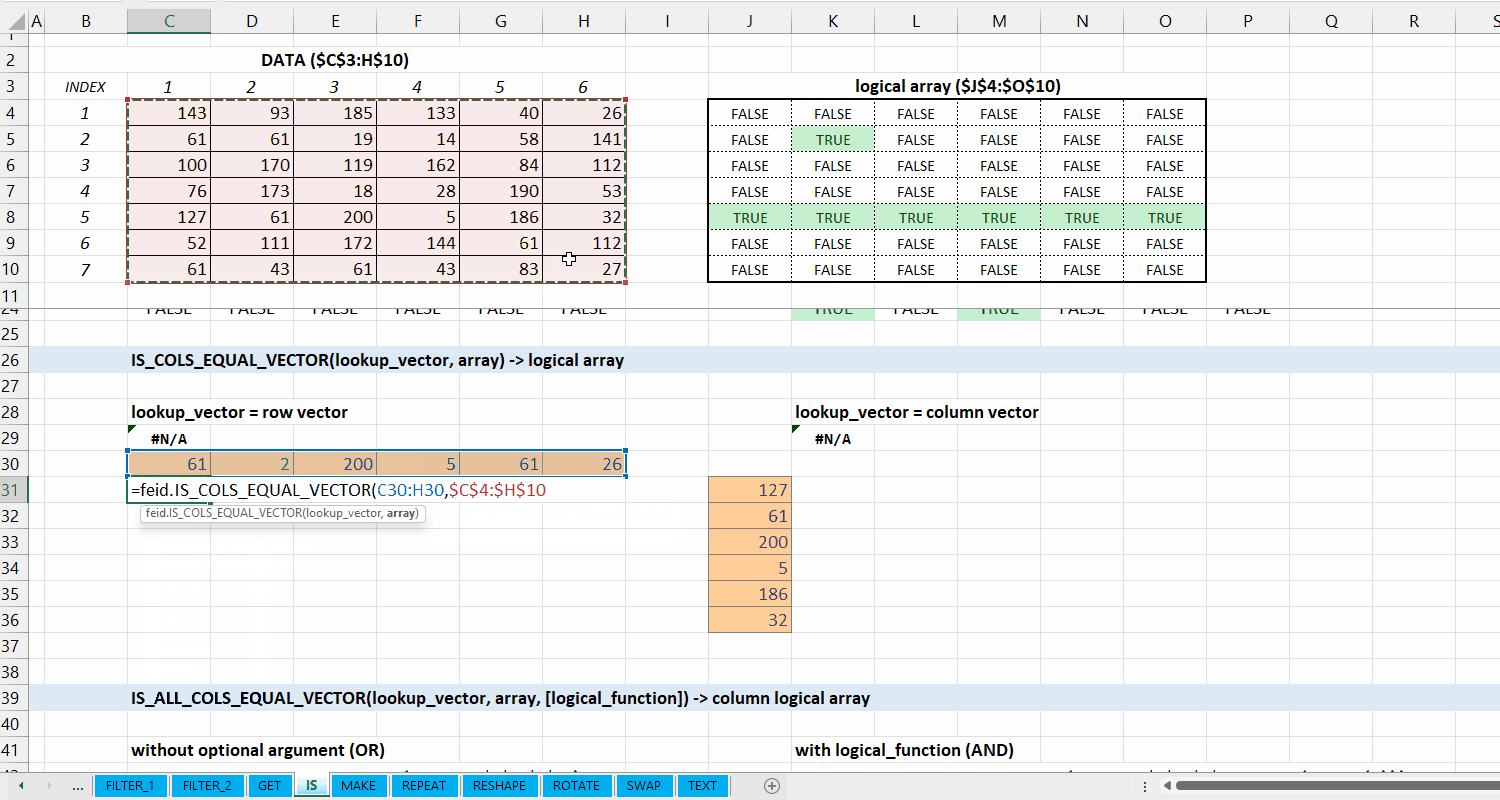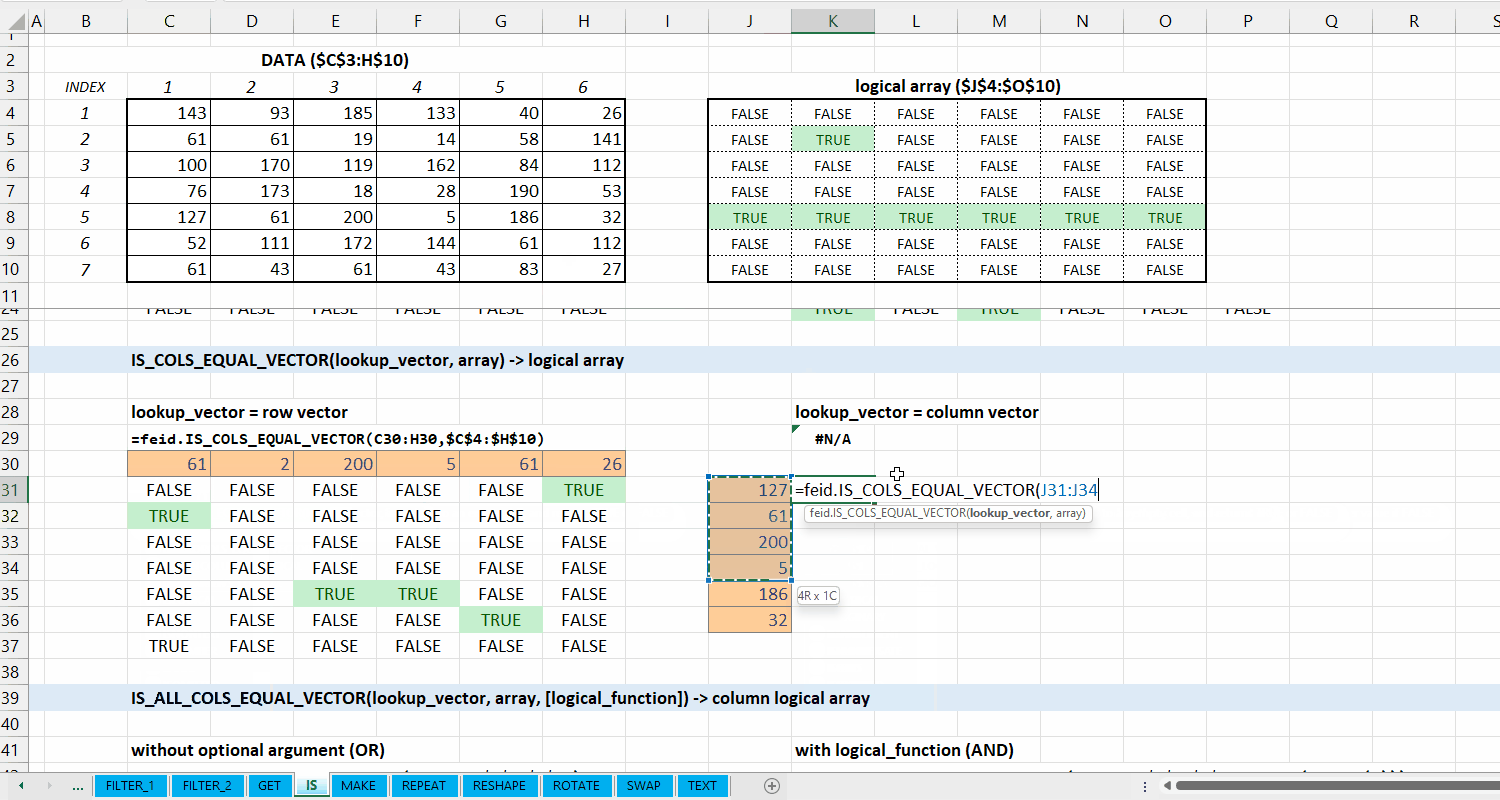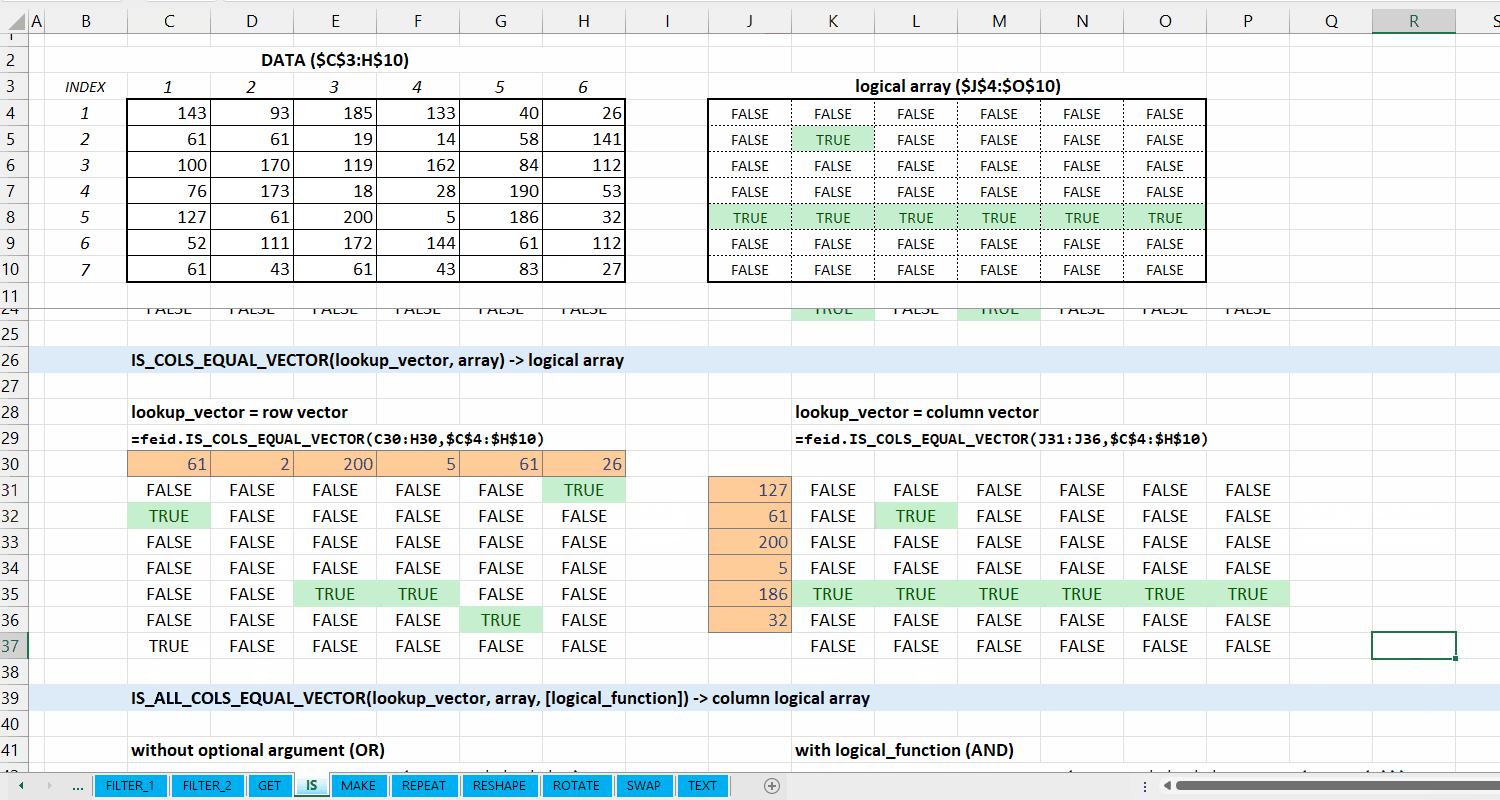
IS_COLS_EQUAL_VECTOR()
Fungsi IS_COLS_EQUAL_VECTOR(lookup_vector, array) digunakan untuk memeriksa apakah setiap kolom di array termasuk dari setiap elemen di lookup_vector.
Syntax
IS_COLS_EQUAL_VECTOR(lookup_vector, array)
Output
logical array
lookup_vector := [vector]
Vector yang terdiri dari nilai yang ingin dicocokkan. Jumlah elemen lookup_vector harus sama dengan jumlah kolom array.
array := [array | vector]
Data berupa array .
Gambar 5.3: Demonstrasi IS_COLS_EQUAL_VECTOR()
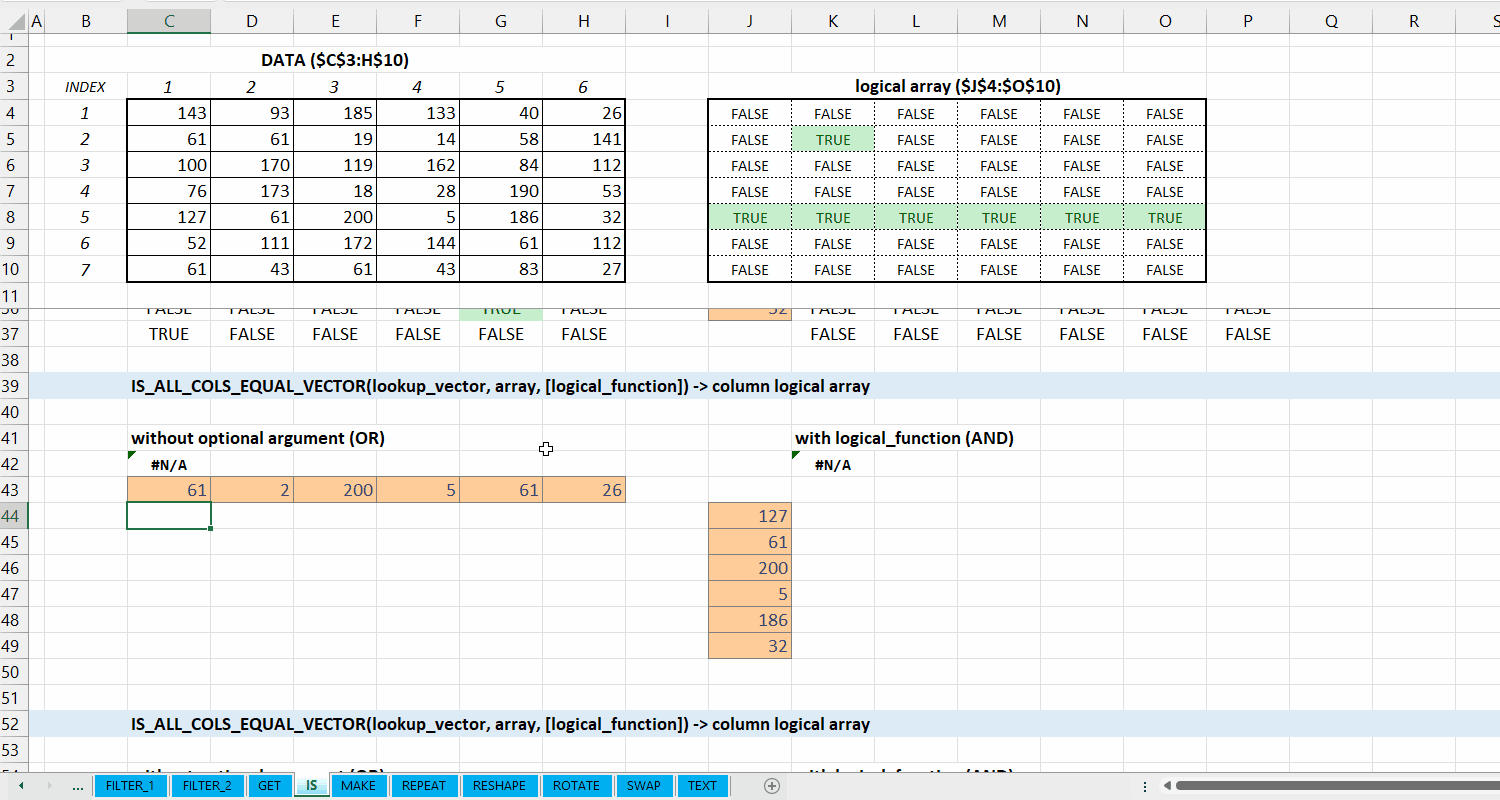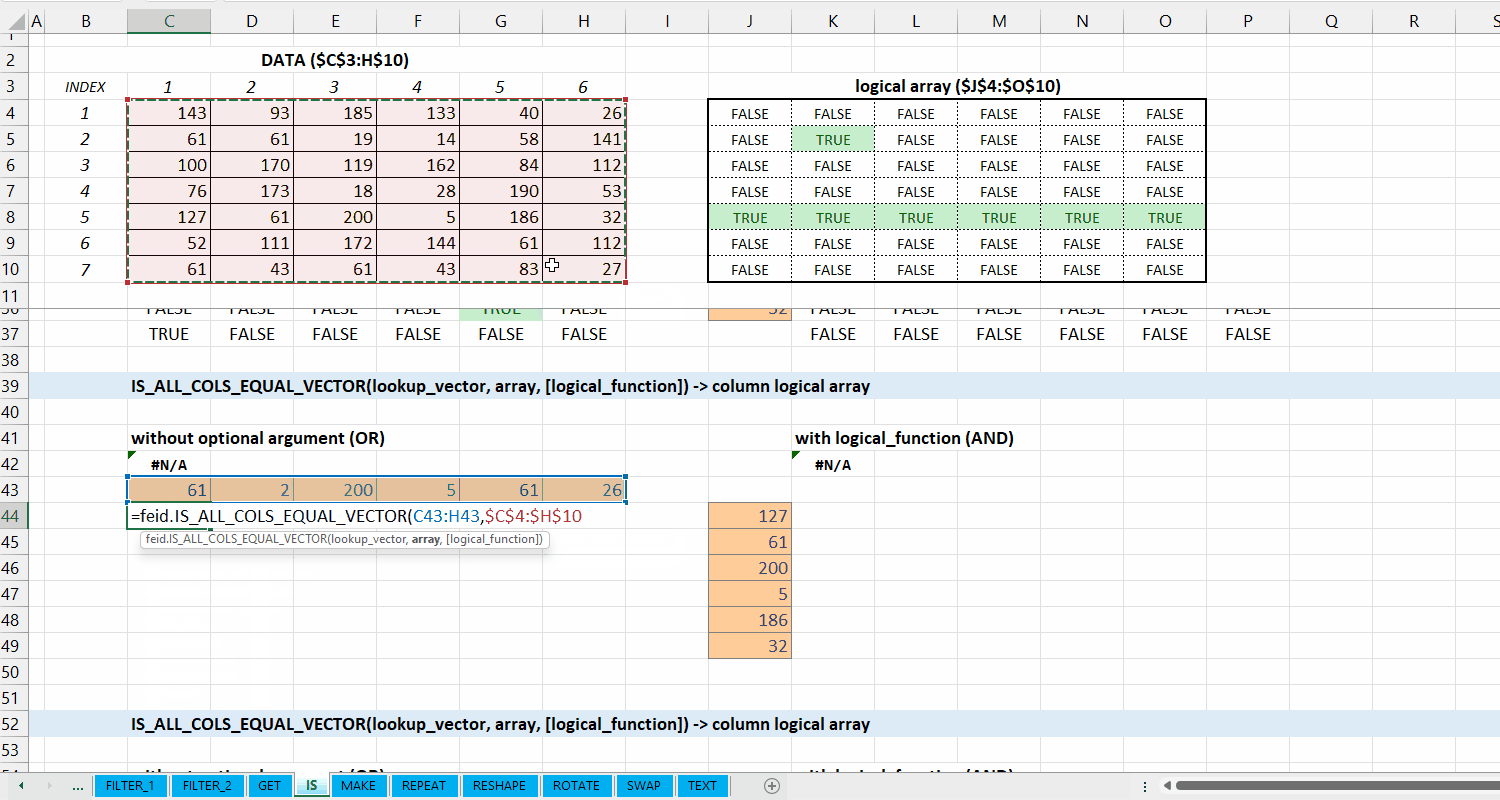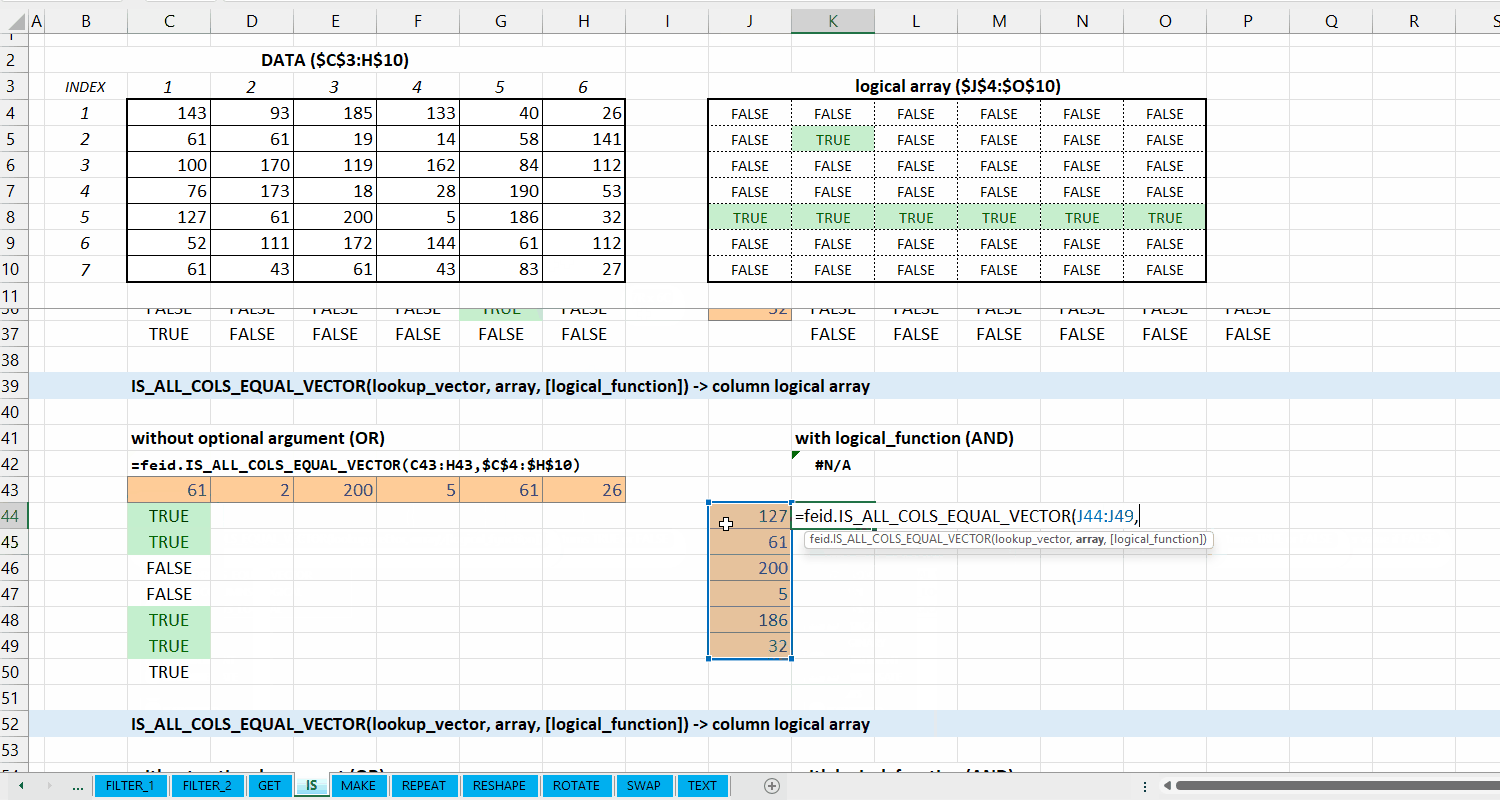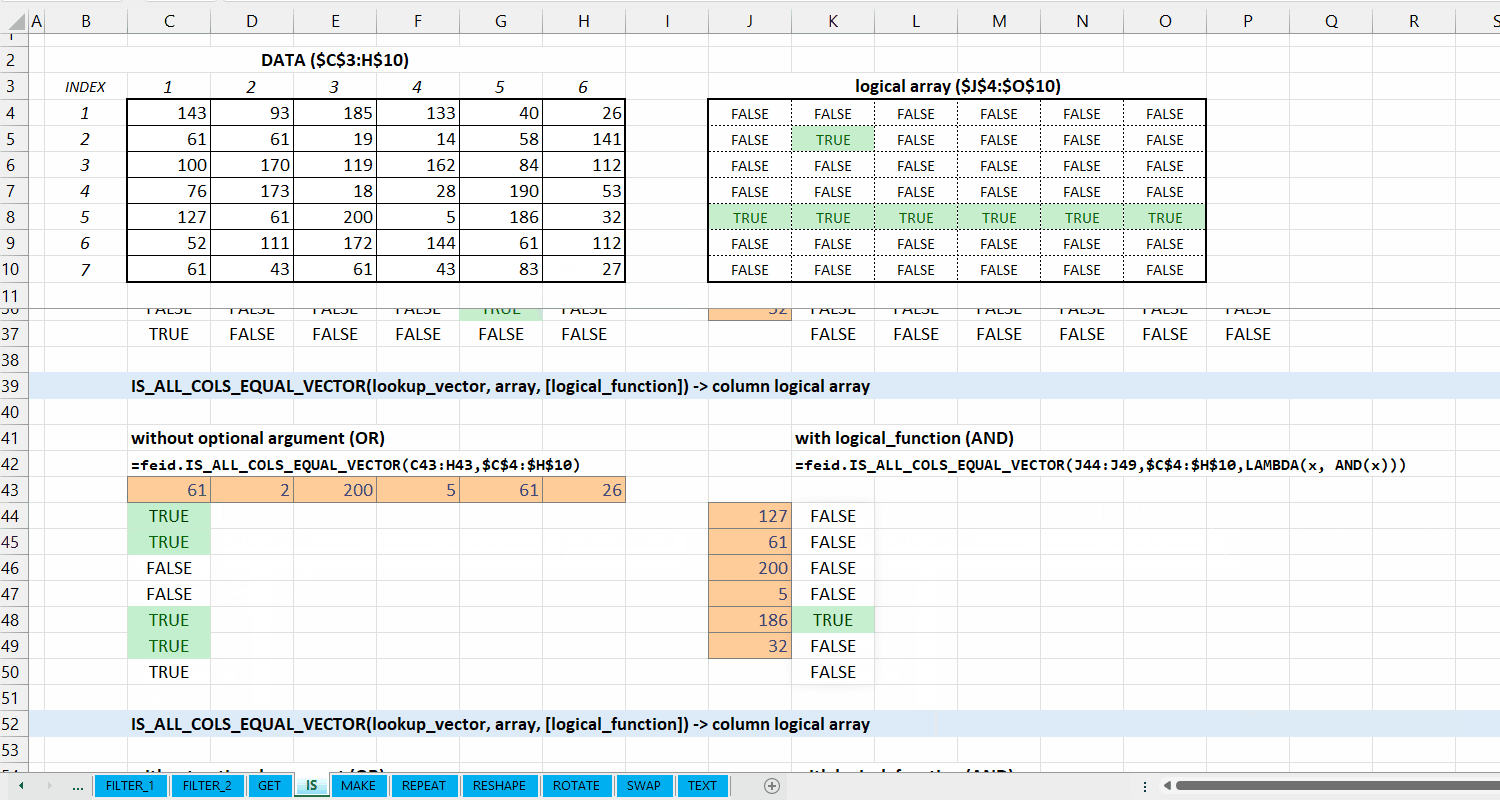
IS_ALL_COLS_EQUAL_VECTOR()
Fungsi IS_ALL_COLS_EQUAL_VECTOR(lookup_vector, array, [logical_function]) digunakan untuk memeriksa apakah setiap kolom di array termasuk dari setiap elemen di lookup_vector, dan diperiksa apakah setiap barisnya sesuai dengan logical_function. Fungsi ini menggunakan fungsi IS_COLS_EQUAL_VECTOR().
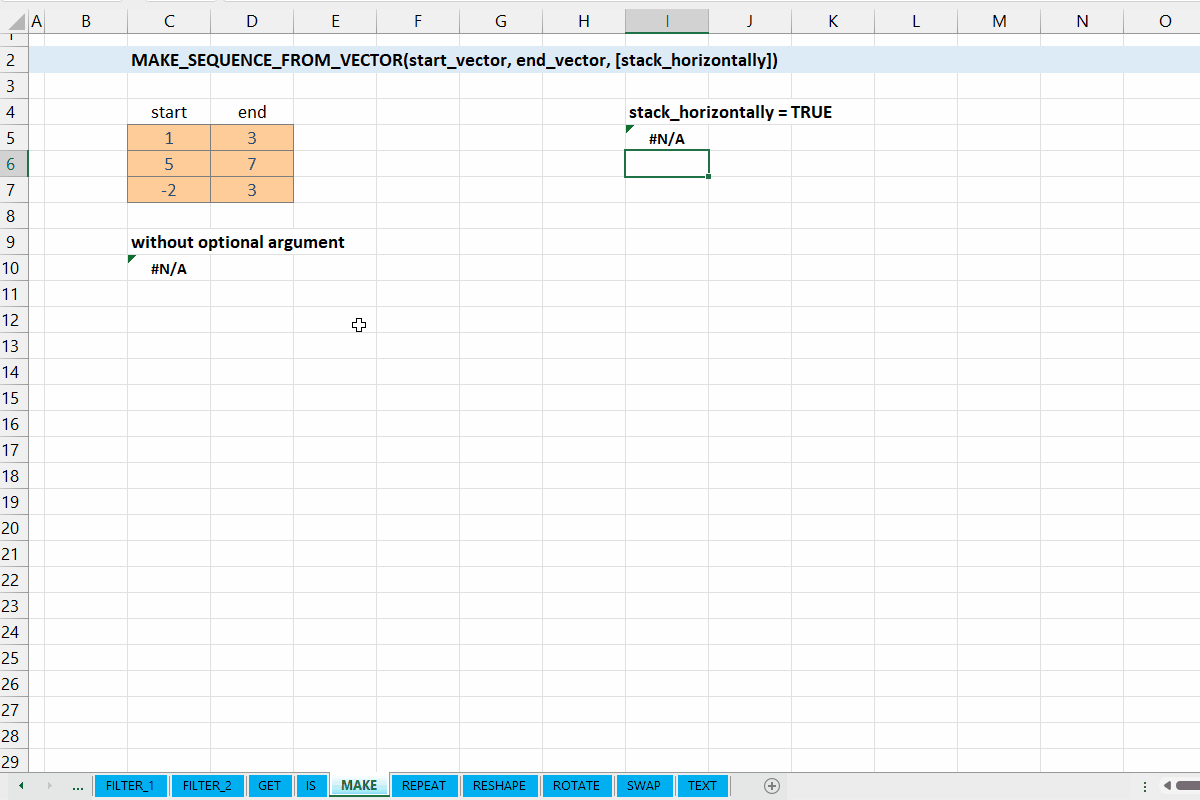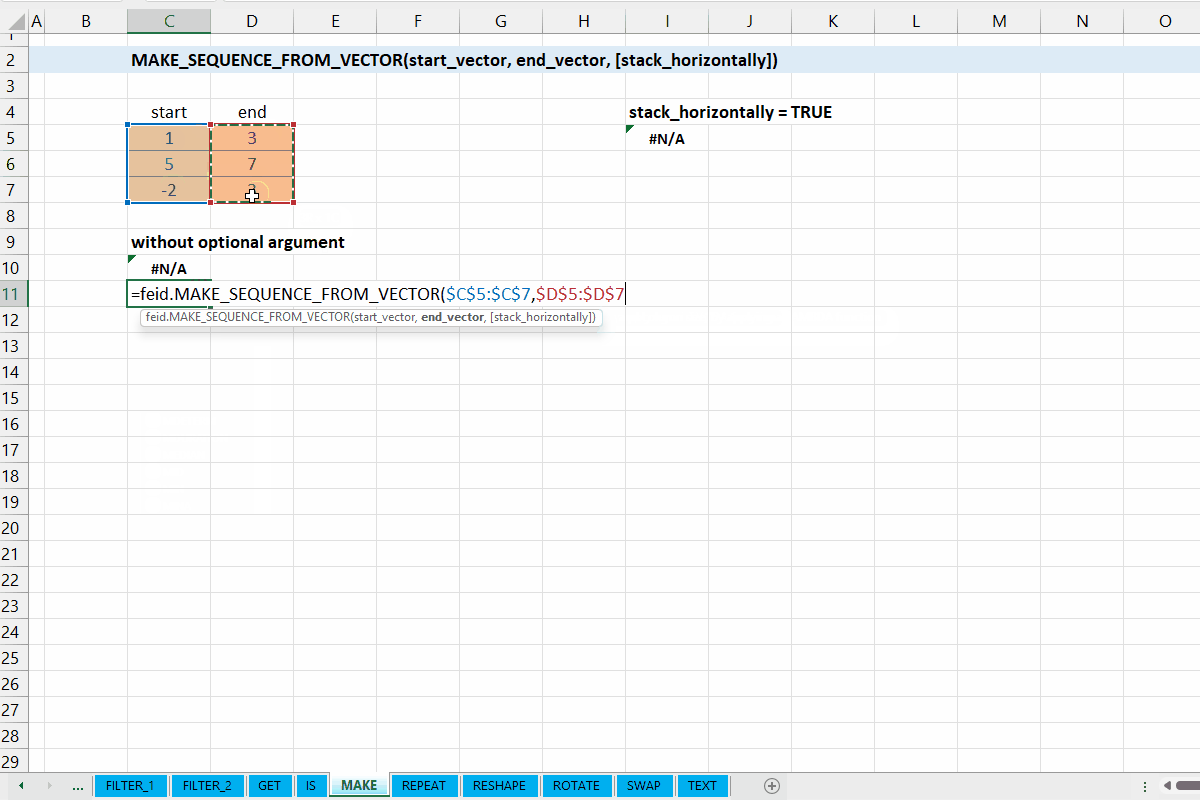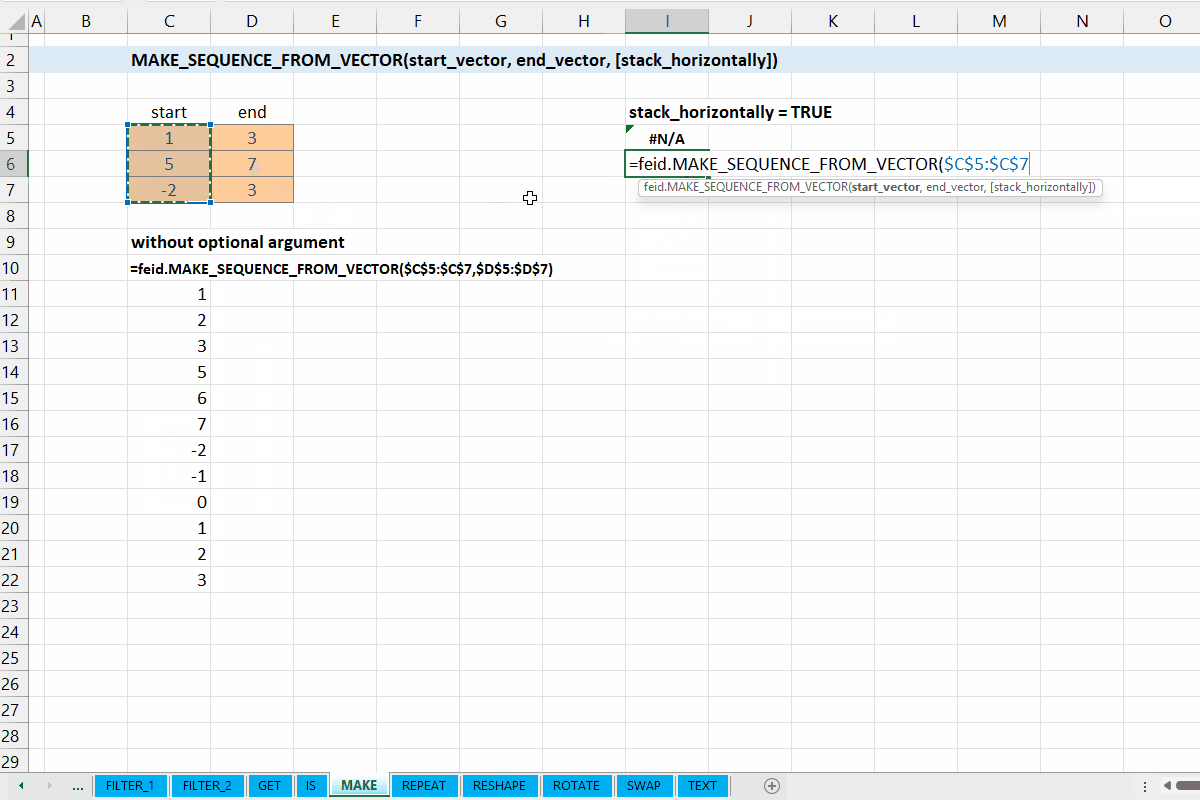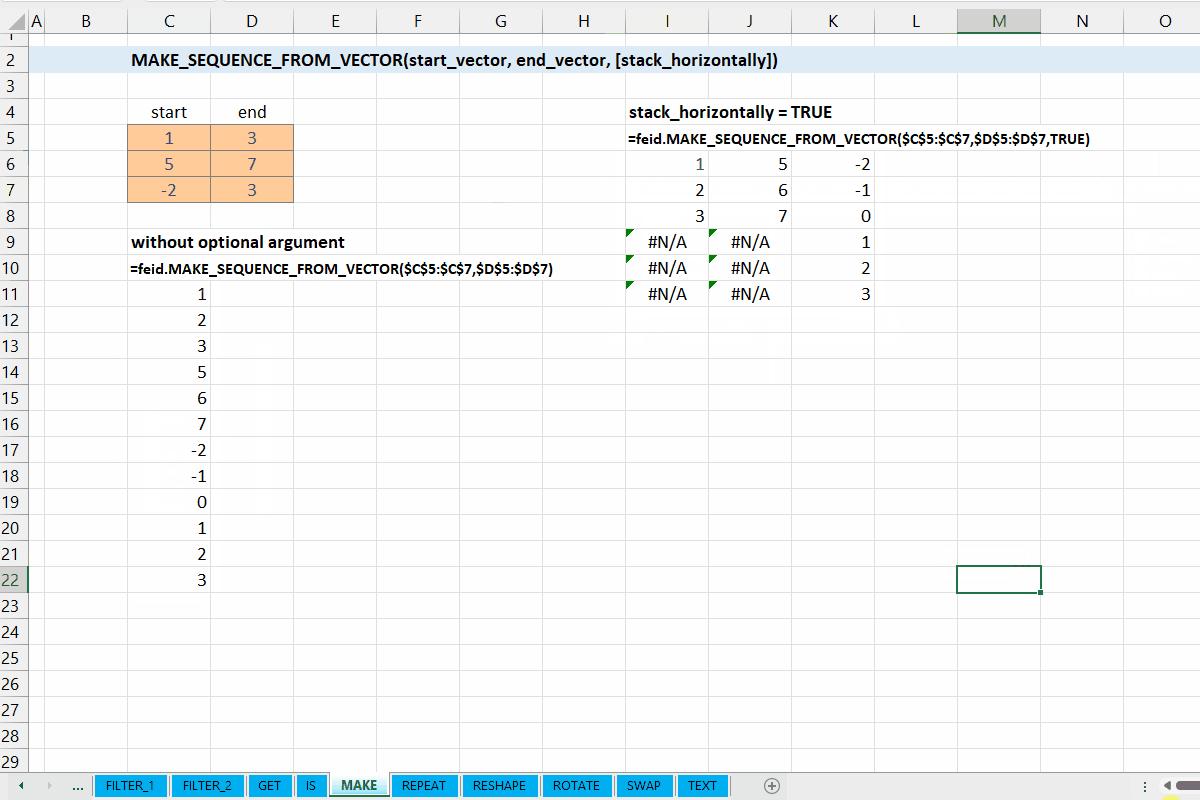
Fungsi MAKE_SEQUENCE_FROM_VECTOR(start_vector, end_vector, [stack_horizontally]) digunakan untuk mebangkitkan sequence dari setiap baris/elemen di start_vector dan end_vector.
Vector yang terdiri dari bilangan bulat memulai sequence.
end_vector := [integer vector]
Vector yang terdiri dari bilangan bulat akhir sequence.
[stack_horizontally] := FALSE :: [TRUE | FALSE]
Nilai default yaitu FALSE. Jika TRUE, maka setiap sequence yang dibangkitkan akan disusun horizontal.
Gambar 6.2: Demonstrasi MAKE_SEQUENCE_FROM_VECTOR()
Kategori REPEAT_*
Kategori REPEAT_* merupakan kumpulan fungsi yang digunakan untuk melakukan pengulangan array ataupun vector dan menghasilkannya dalam bentuk dynamic array. Hubungan antar fungsi di kategori ini bisa dilihat di Gambar 7.1.
Fungsi REPEAT_ARRAY_BY_ROW(array, [num_repeat]) digunakan untuk mengulangi array sepanjang baris (ke bawah).
Syntax
REPEAT_ARRAY_BY_ROW(array, [num_repeat])
Output
array
array := [scalar | vector | array]
Data dapat berupa scalar, vector, ataupun array.
[num_repeat] := 2 :: [integer]
Nilai default yaitu 2. Jumlah pengulangannya.
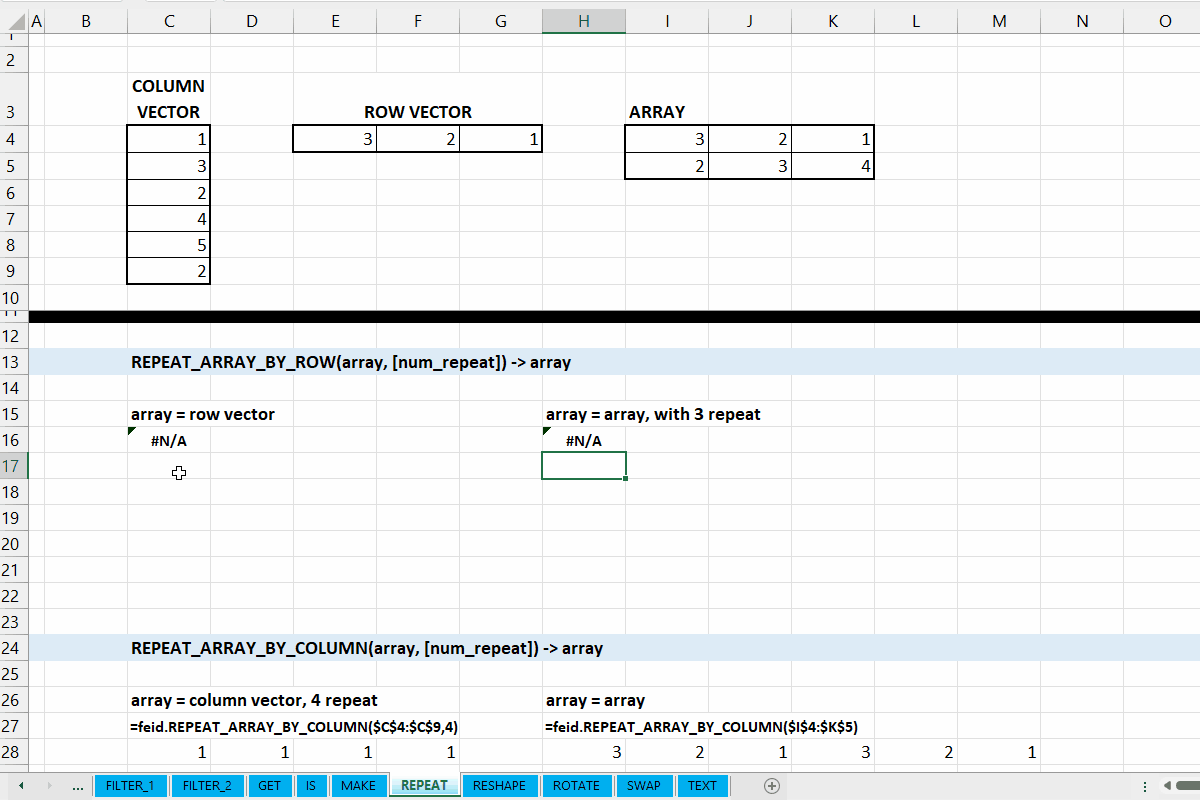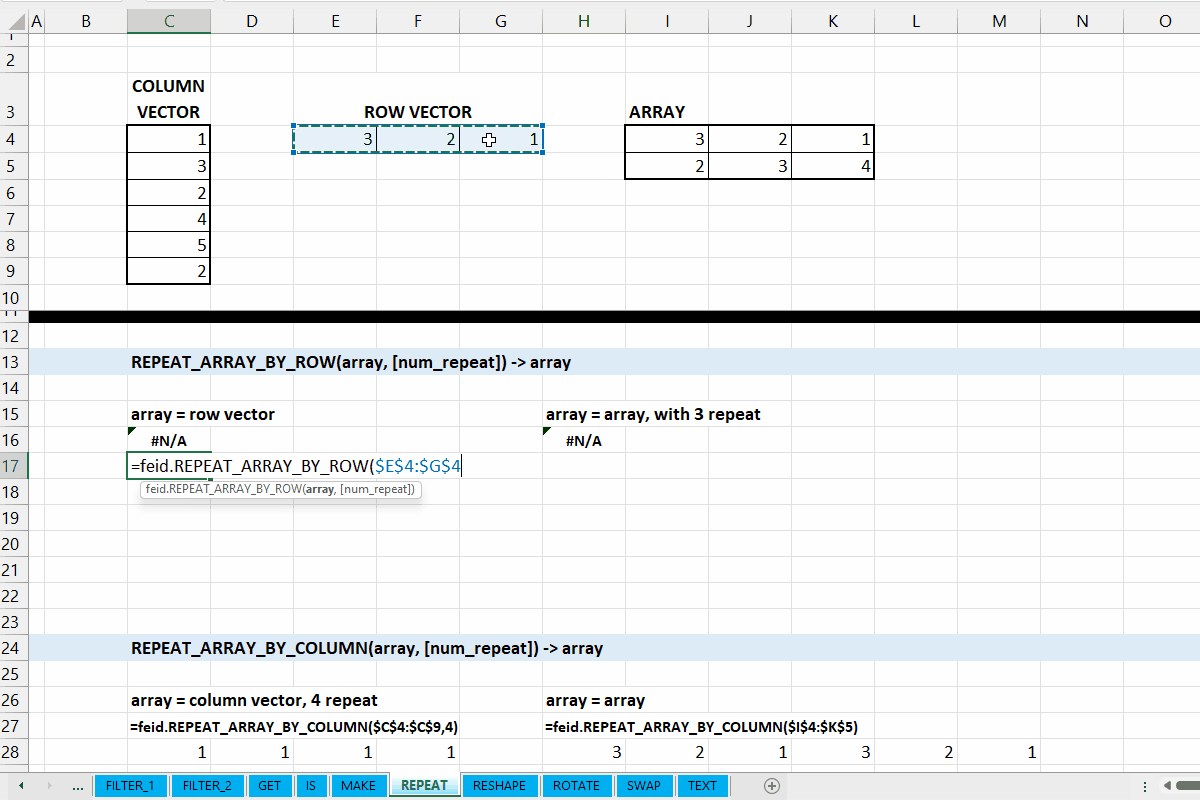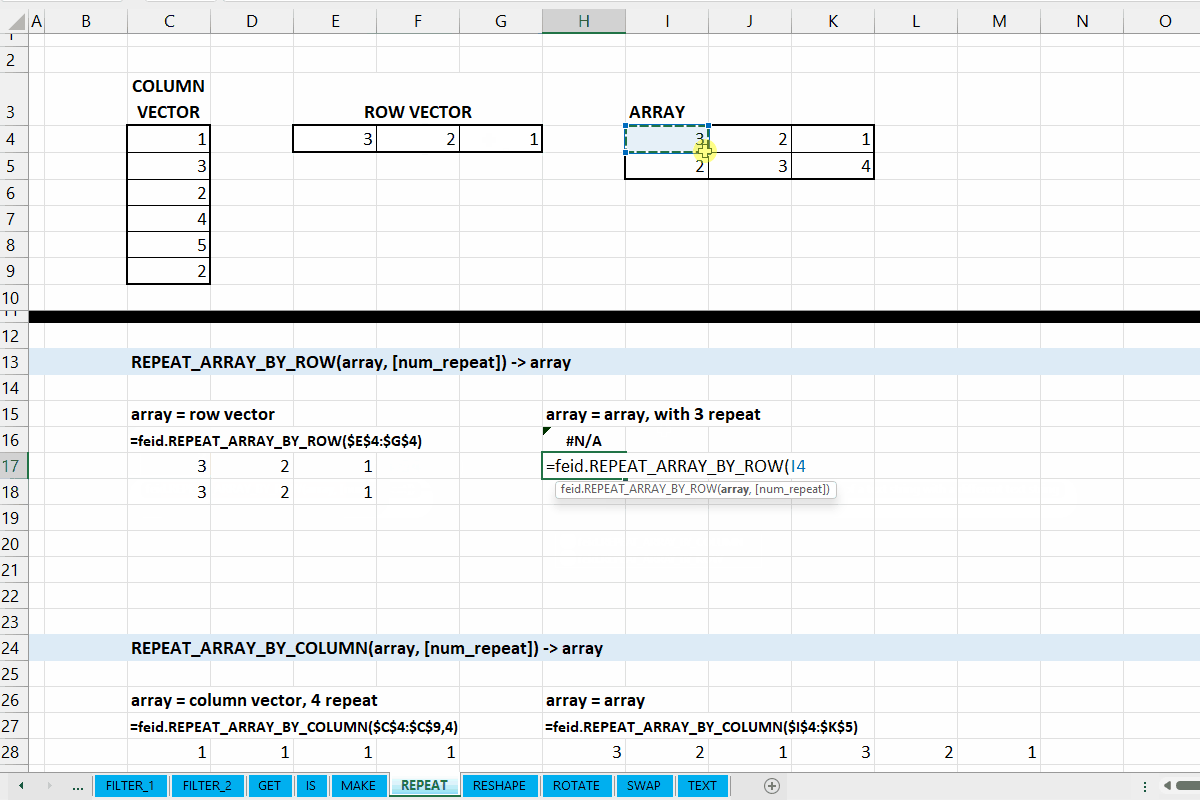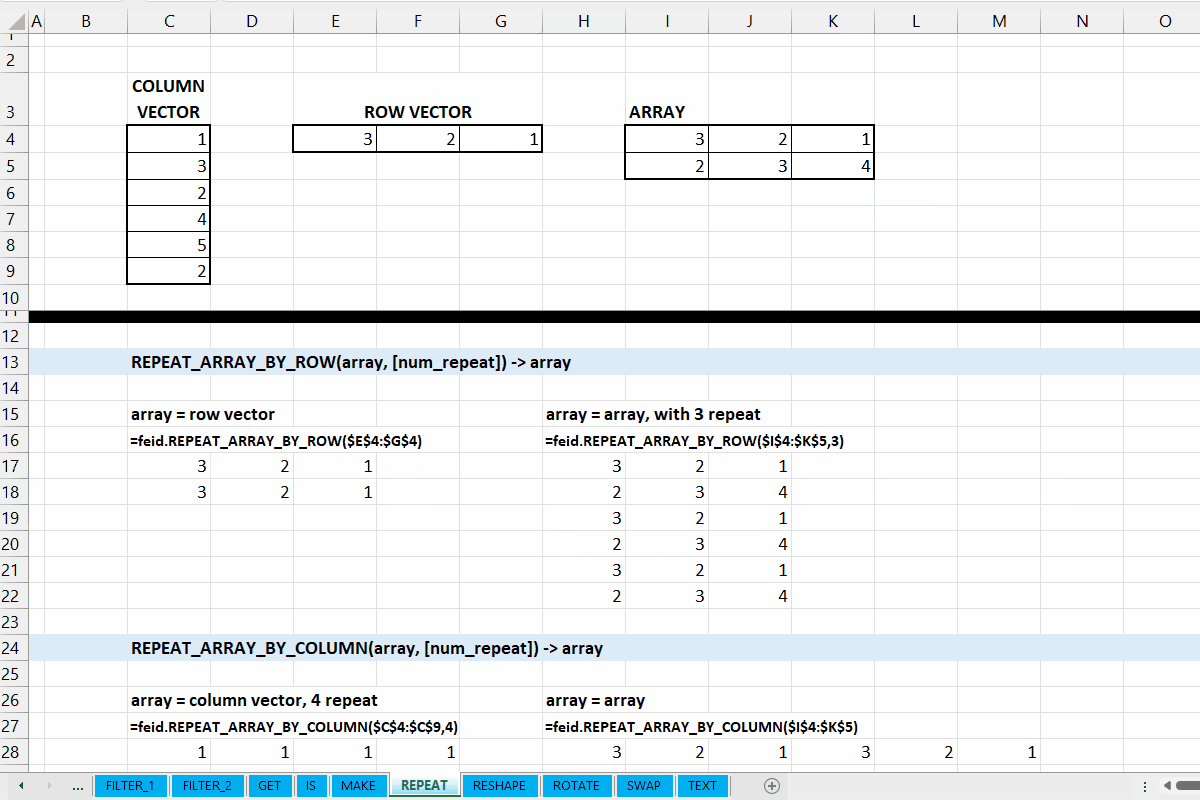
Gambar 7.2: Demonstrasi REPEAT_ARRAY_BY_ROW()
REPEAT_ARRAY_BY_COLUMN()
Fungsi REPEAT_ARRAY_BY_COLUMN(array, [num_repeat]) digunakan untuk mengulangi array sepanjang kolom (ke kanan).
Syntax
REPEAT_ARRAY_BY_COLUMN(array, [num_repeat])
Output
array
array := [scalar | vector | array]
Data dapat berupa scalar, vector, ataupun array.
[num_repeat] := 2 :: [integer]
Nilai default yaitu 2. Jumlah pengulangannya.
Gambar 7.3: Demonstrasi REPEAT_ARRAY_BY_COLUMN()
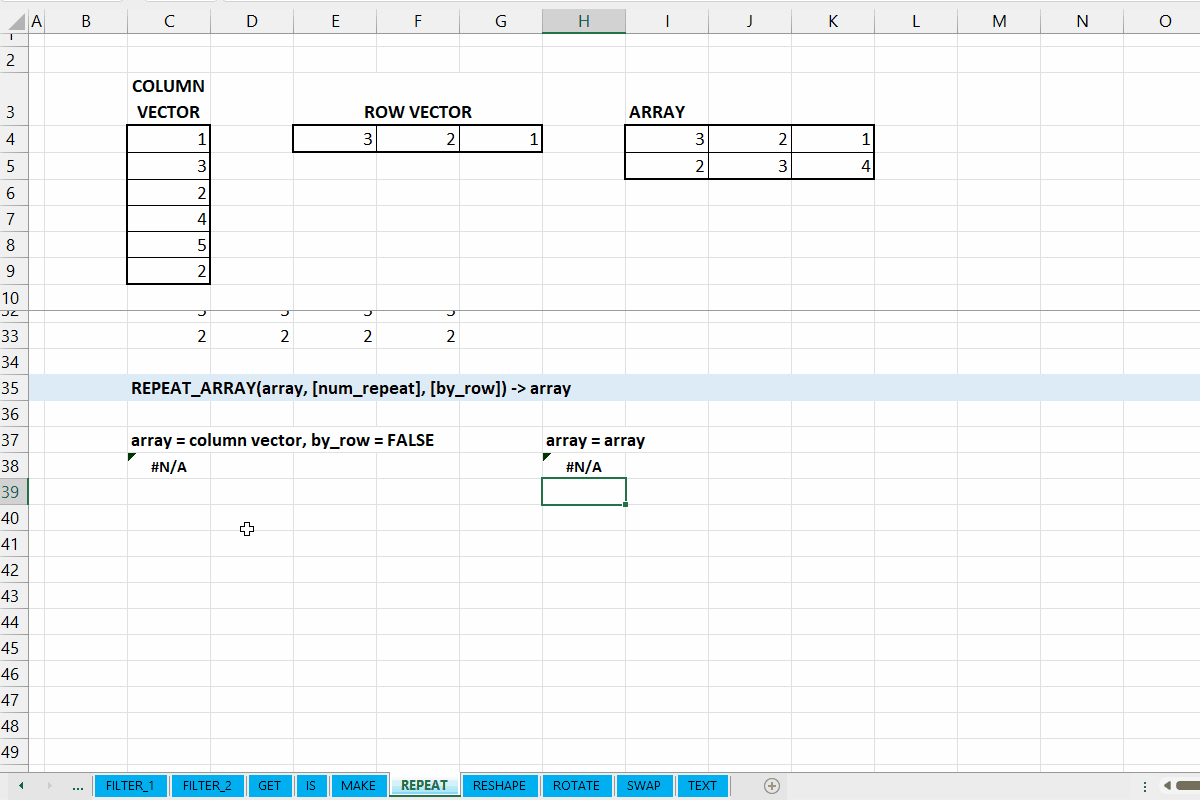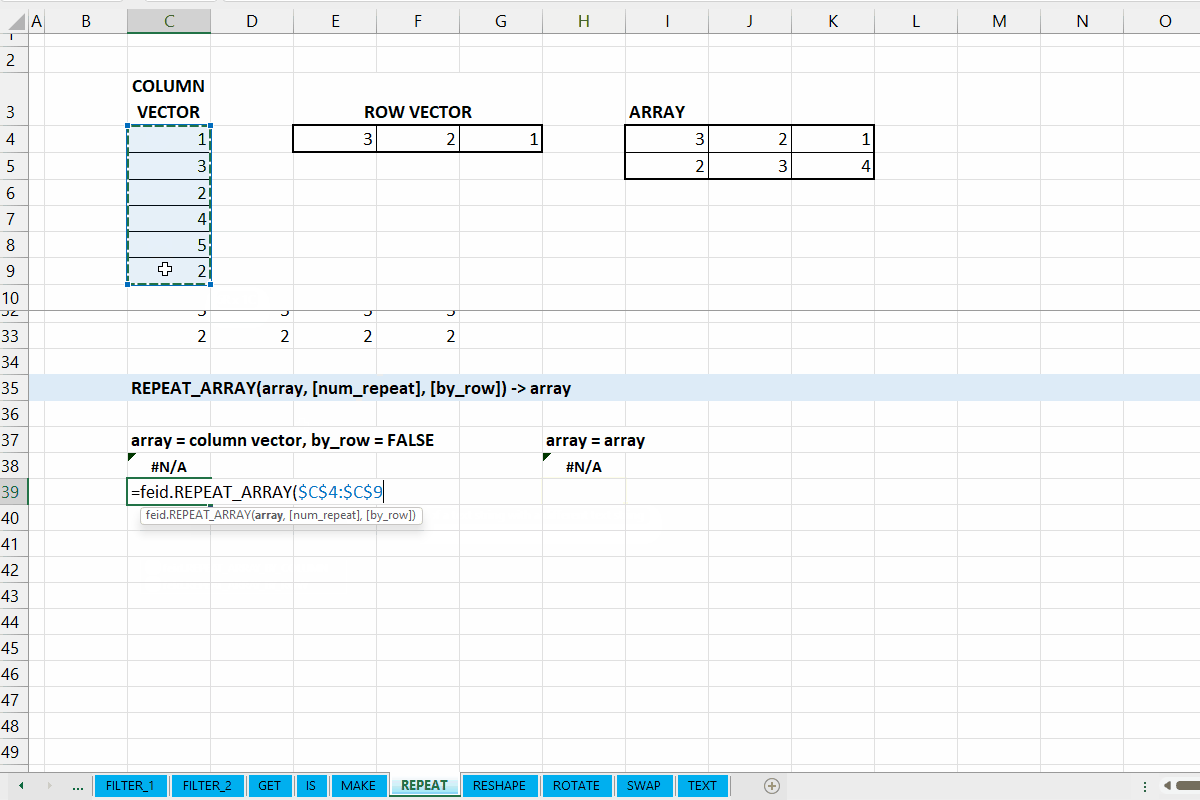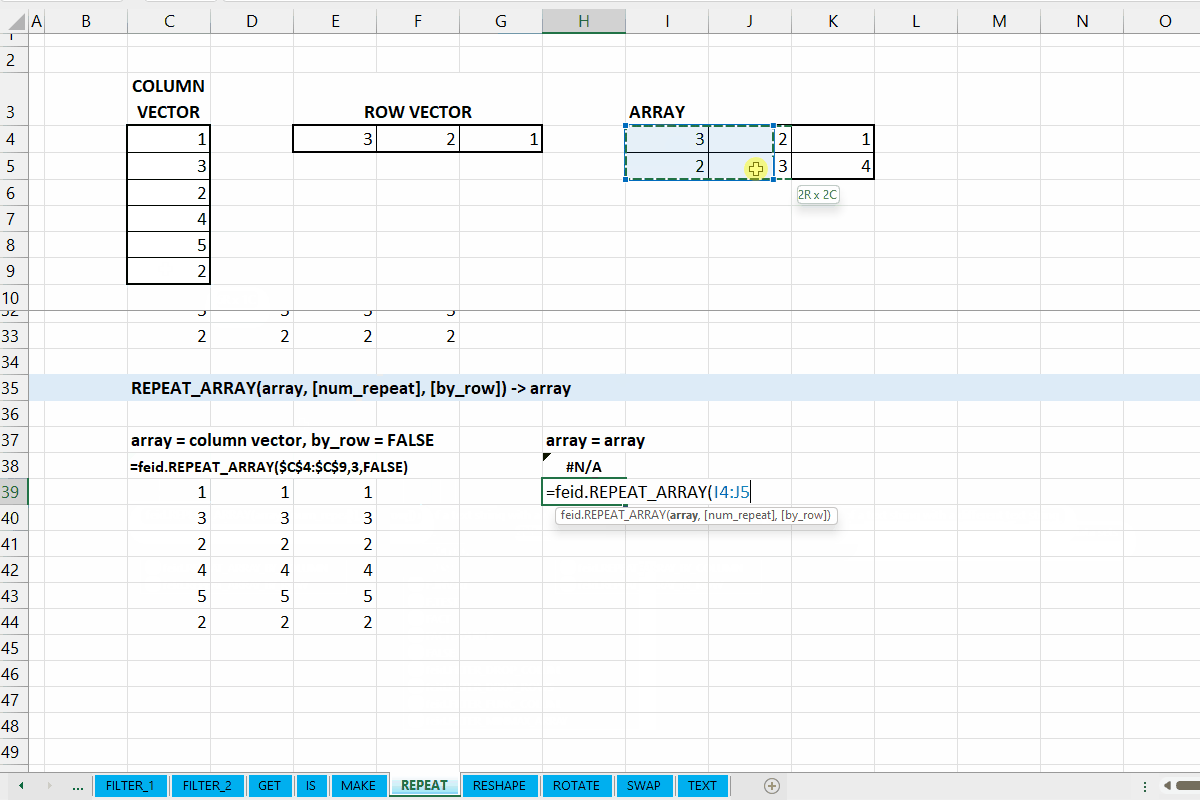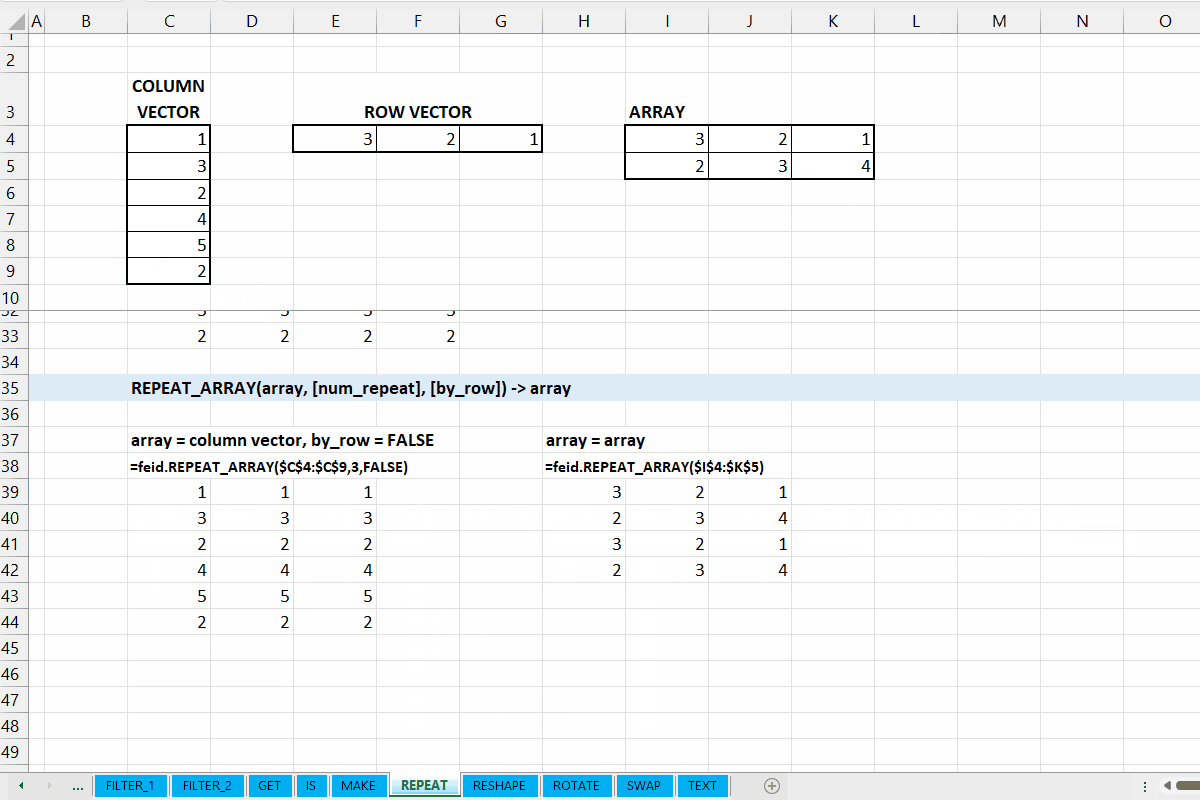
REPEAT_ARRAY()
Fungsi REPEAT_ARRAY(array, [num_repeat], [by_row]) digunakan untuk mengulangi array sepanjang baris/kolom (ke bawah/ke kanan).
Syntax
REPEAT_ARRAY(array, [num_repeat], [by_row])
Output
array
array := [scalar | vector | array]
Data dapat berupa scalar, vector, ataupun array.
[num_repeat] := 2 :: [integer]
Nilai default yaitu 2. Jumlah pengulangannya.
[by_row] := TRUE :: [TRUE | FALSE]
Nilai default yaitu TRUE. Jika TRUE, maka pengulangan akan sepanjang baris (ke bawah), dan berlaku sebaliknya juga.
Gambar 7.4: Demonstrasi REPEAT_ARRAY()
Kategori RESHAPE_*
Kategori RESHAPE_* merupakan kumpulan fungsi yang dapat digunakan untuk melakukan fungsi logical di data. Hubungan antar fungsi di kategori ini bisa dilihat di Gambar 8.1.
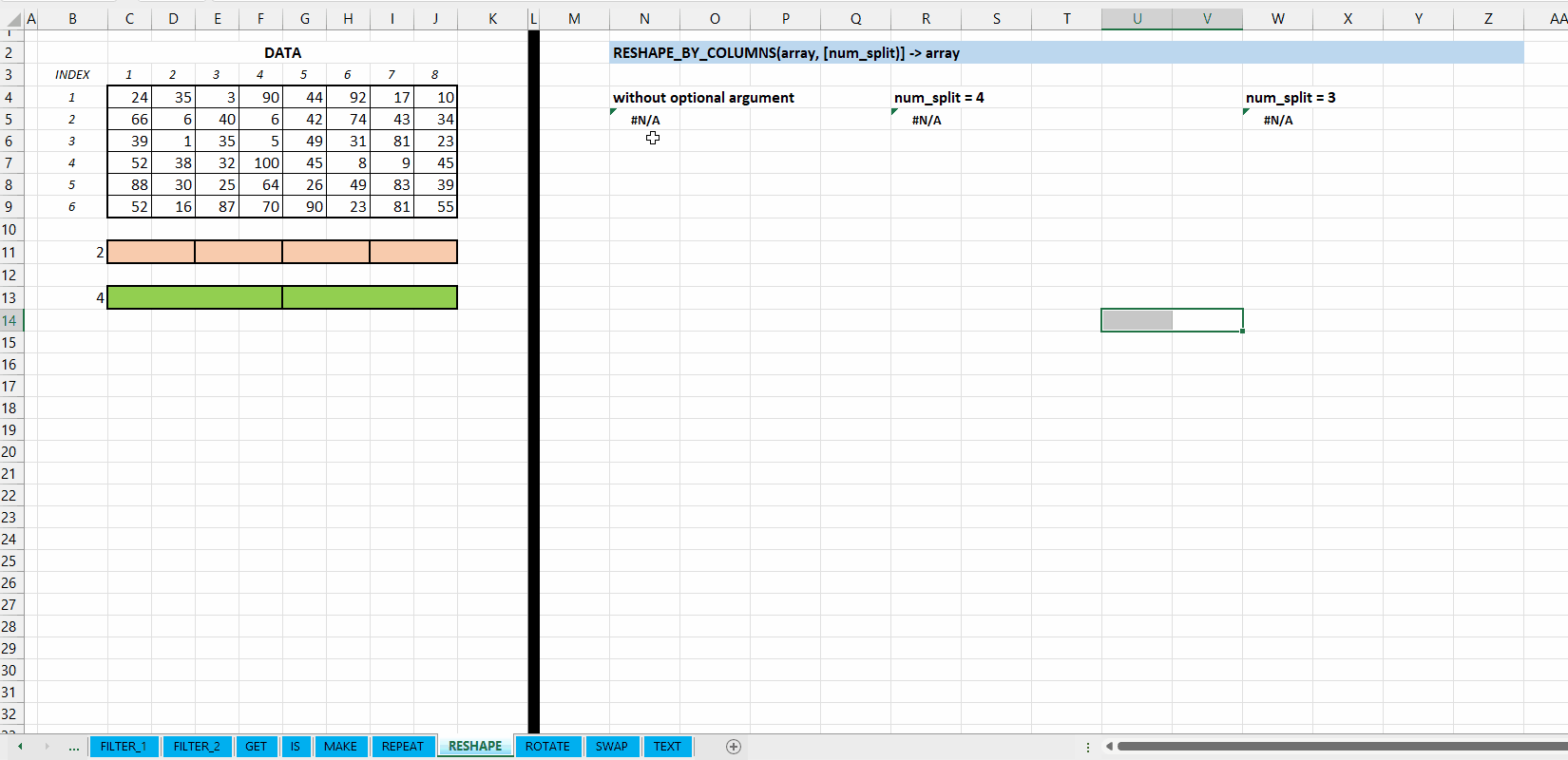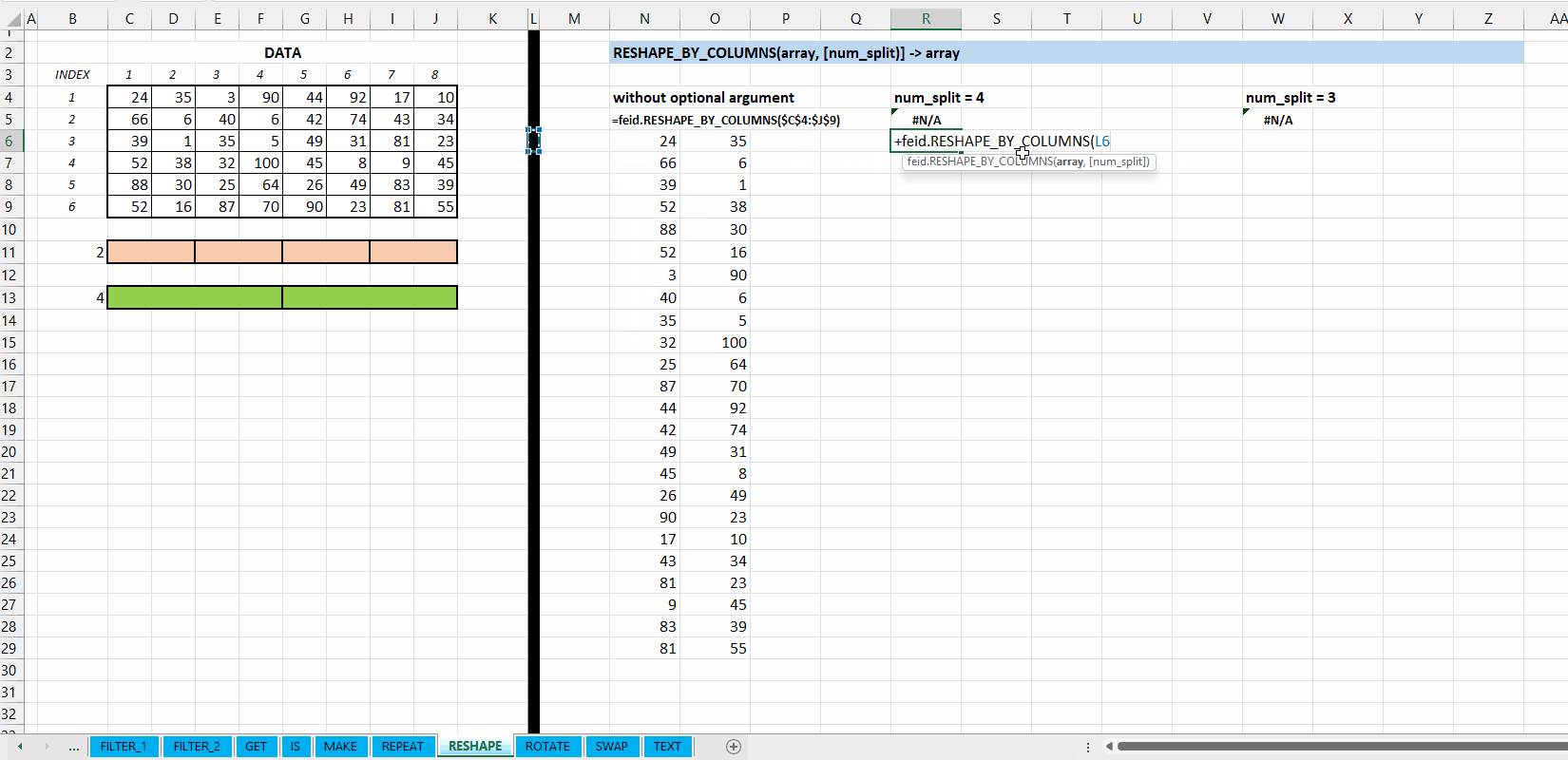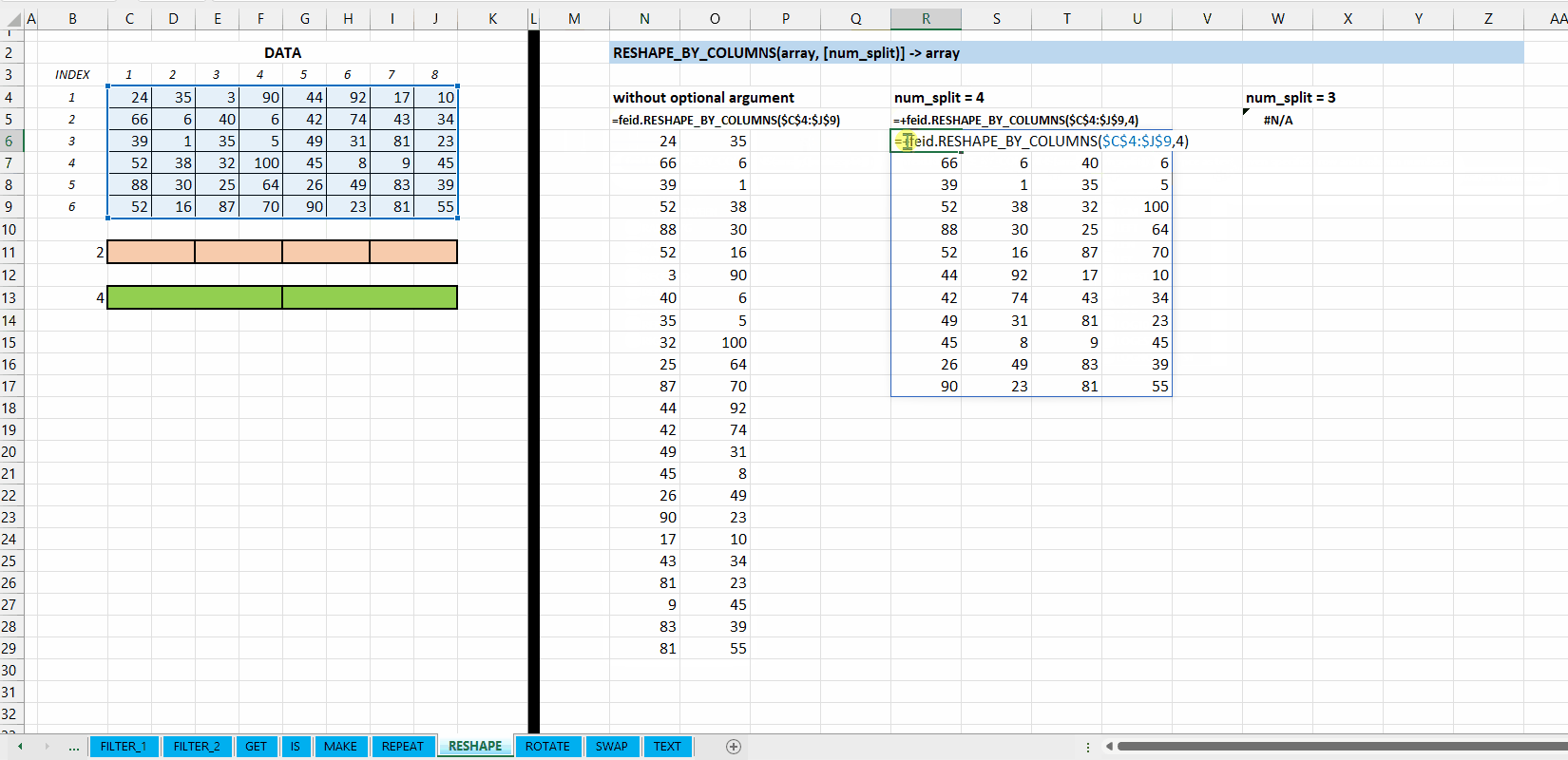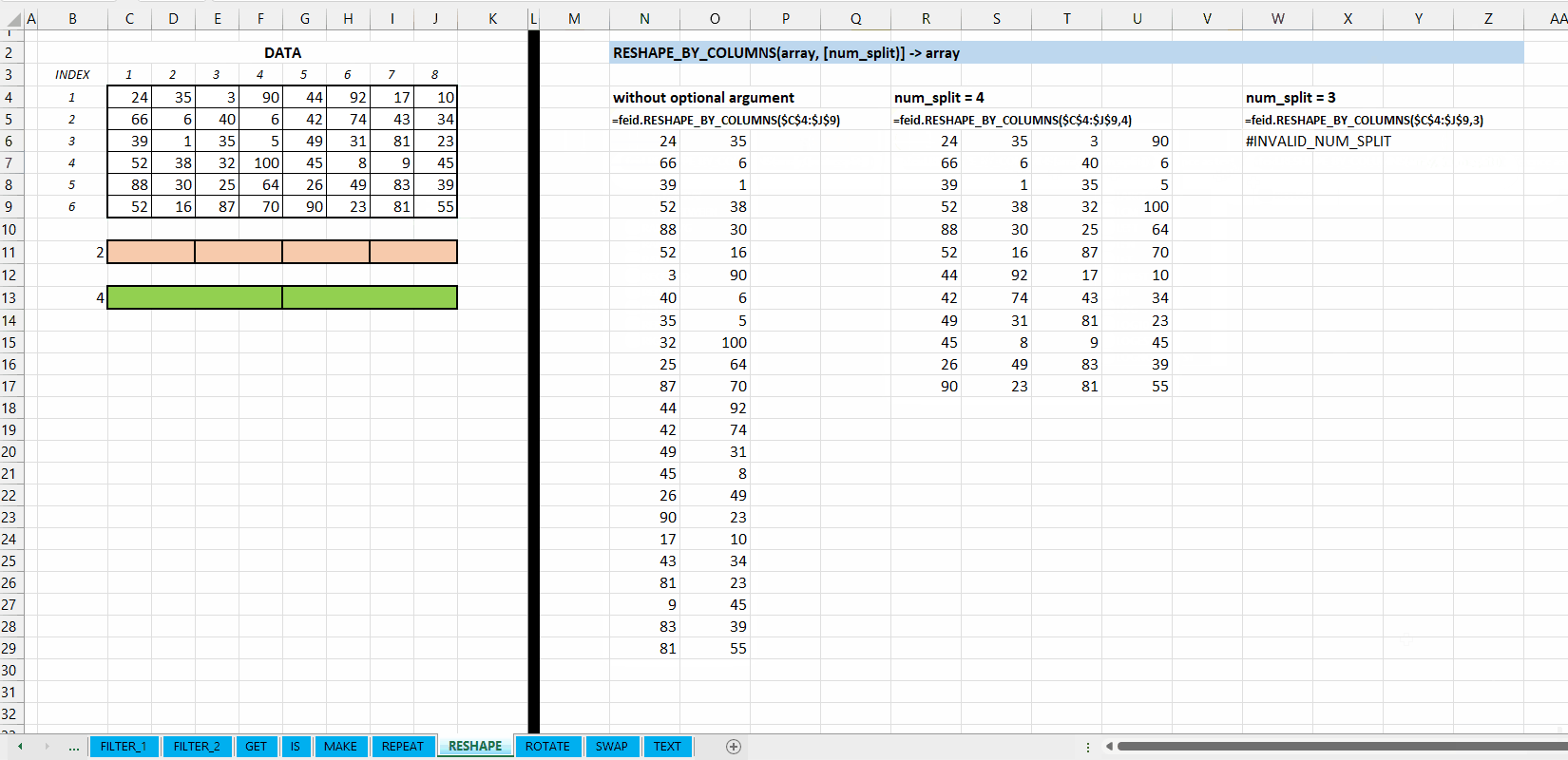
Fungsi RESHAPE_BY_COLUMNS(array, [num_split]) digunakan untuk mengubah dimensi (transformasi) array berdasarkan jumlah pembagi kolomnya. Jika tidak jumlah kolom tidak habis dibagi oleh num_split akan mengeluarkan hasil #N/A.
Syntax
RESHAPE_BY_COLUMNS(array, [num_split])
Output
array
array := [array]
Data berupa array atau vector.
[num_split] := 2 :: [integer]
Nilai default yaitu 2. Jumlah pembagi kolom. Jumlah kolom array harus habis dibagi (MOD()) dengan num_split.
Gambar 8.2: Demonstrasi RESHAPE_BY_COLUMNS()
Kategori ROTATE_*
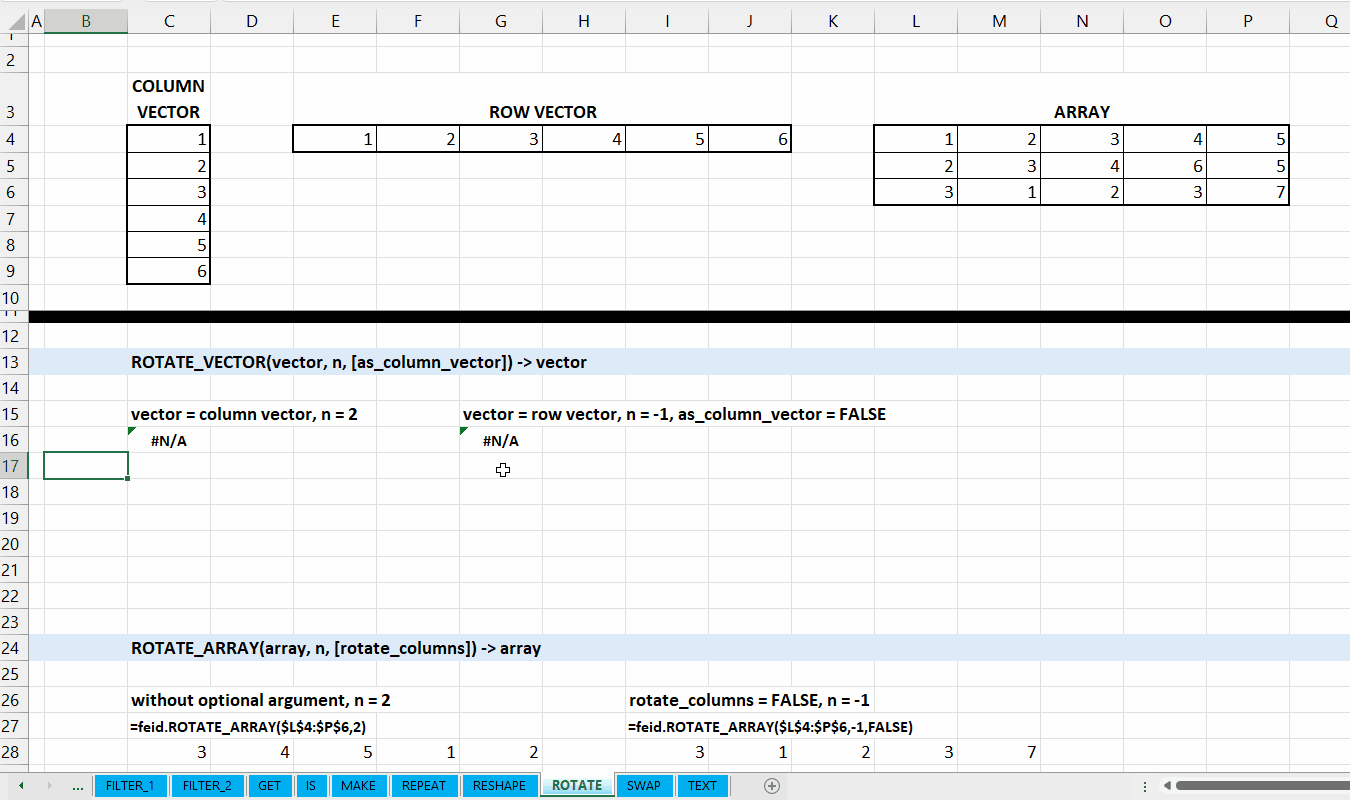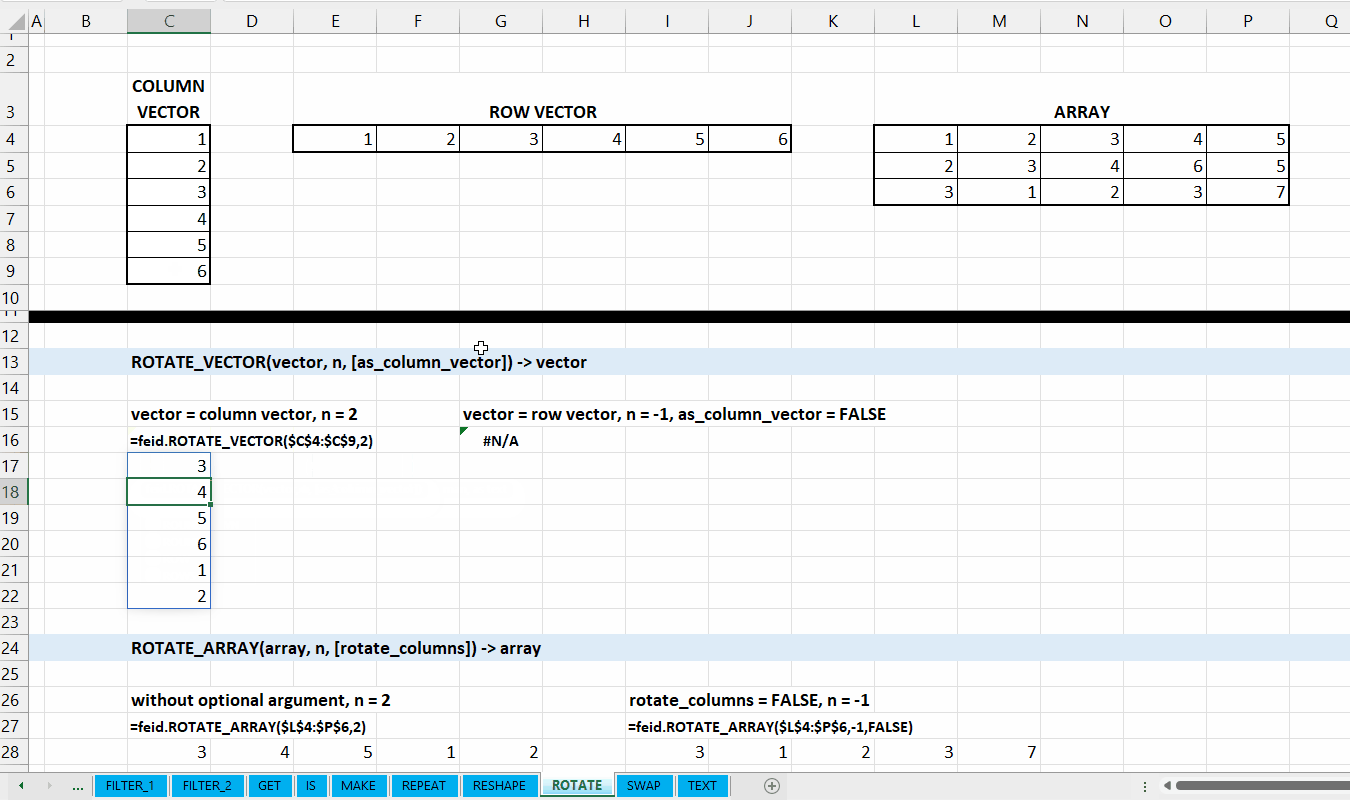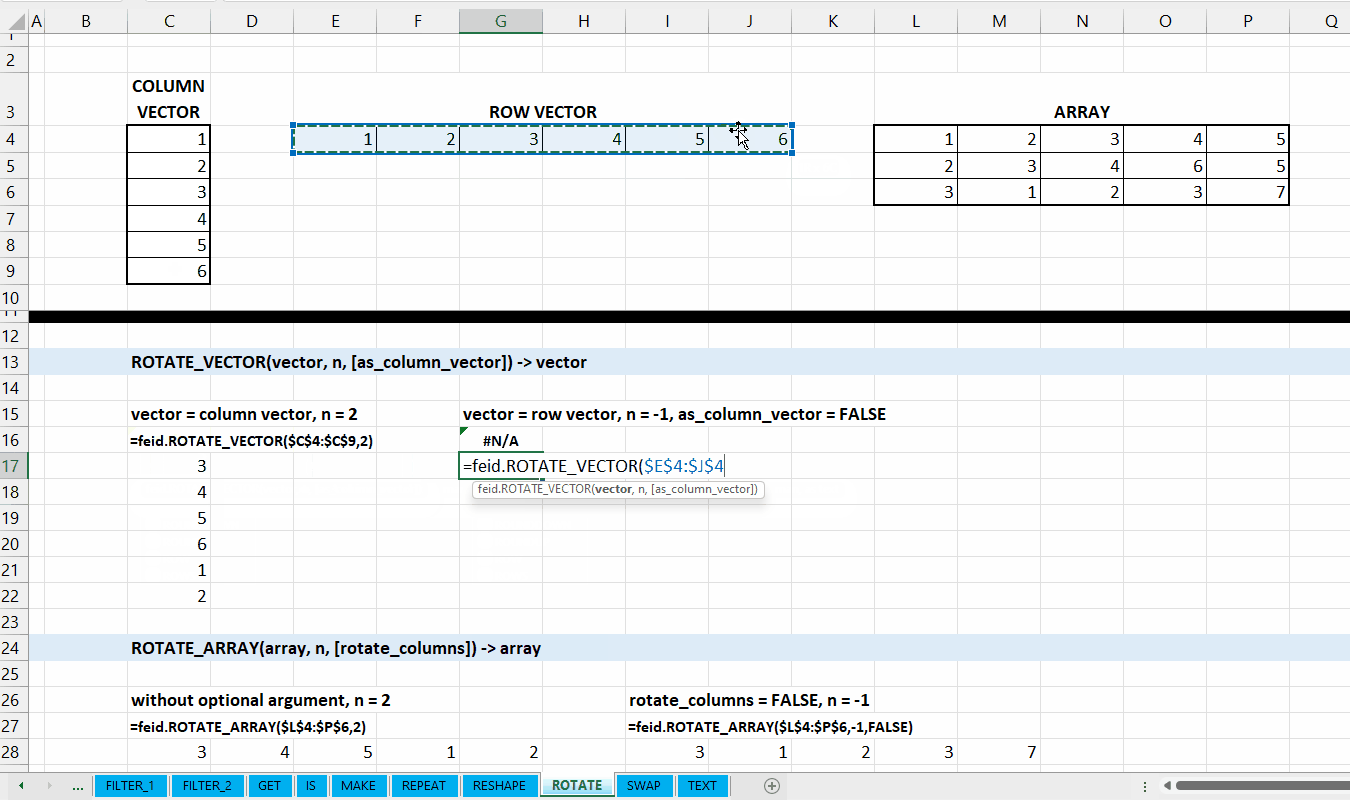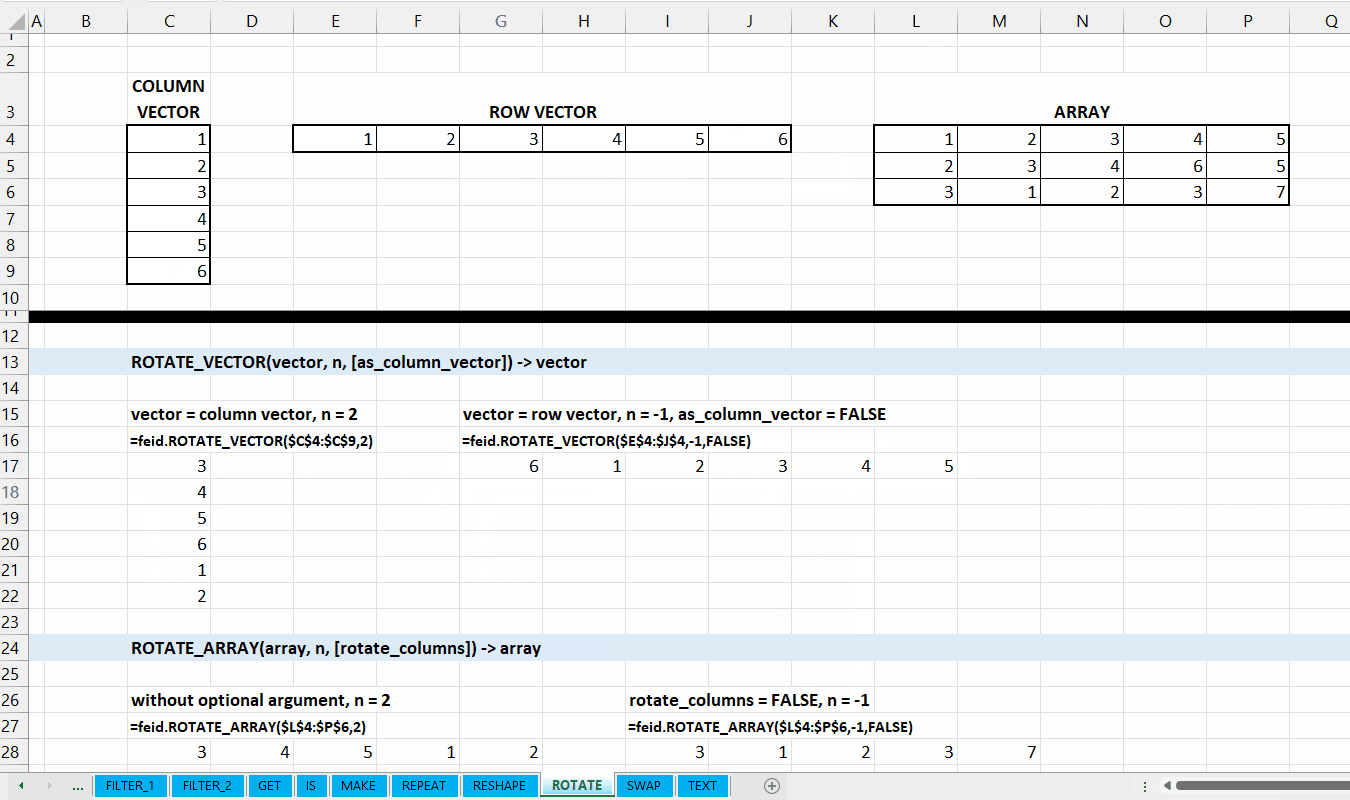
Kategori ROTATE_* merupakan kumpulan fungsi yang digunakan untuk menggeser atau memutar array ataupun vector. Hubungan antar fungsi di kategori ini bisa dilihat di Gambar 9.1.
Data berupa vector (column vector atau row vector).
num_rotation := [integer]
Jumlah berapa kali vector diputar/digeser. Nilai negatif untuk digeser berlawanan arah.
[as_column_vector] := TRUE :: [TRUE | FALSE]
Nilai default yaitu TRUE. Jika TRUE, maka output berupa column vector.
Gambar 9.2: Demonstrasi ROTATE_VECTOR()
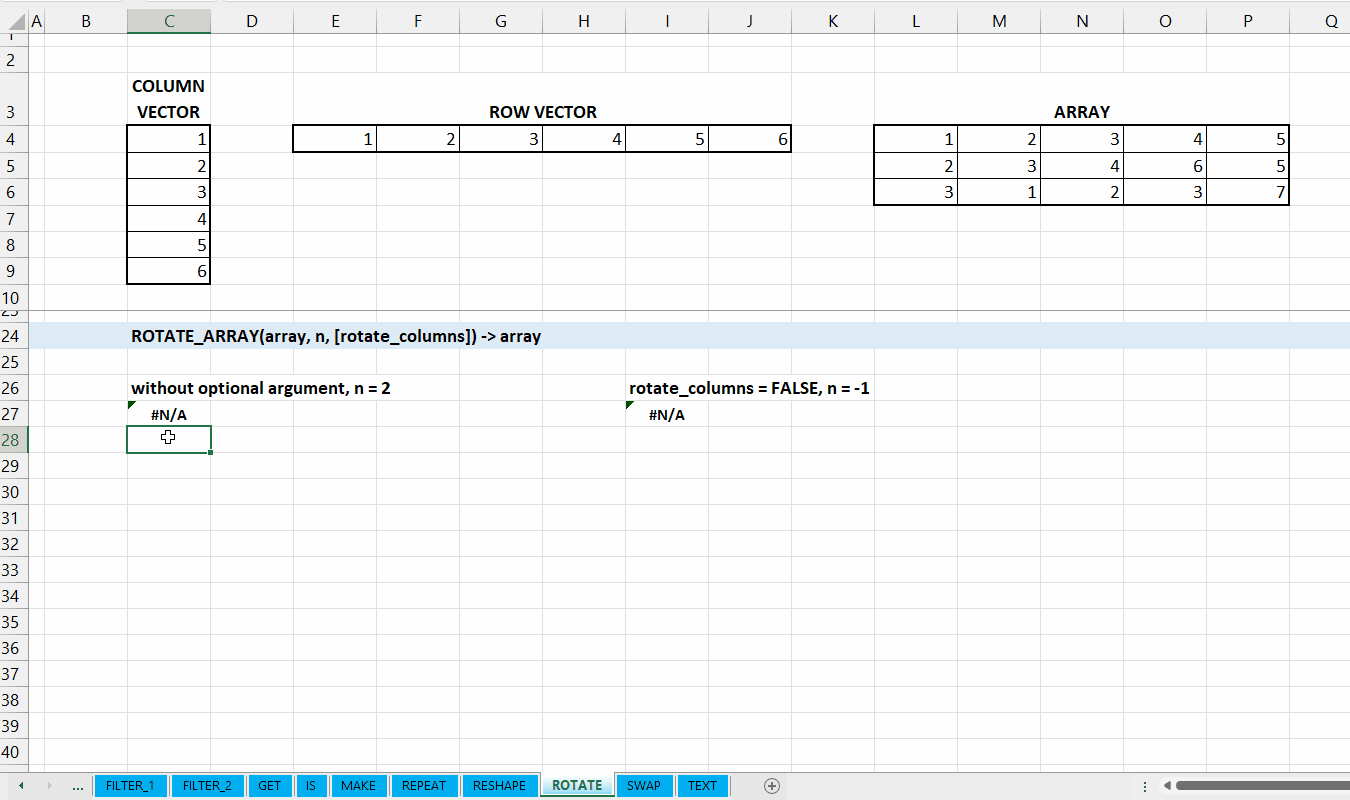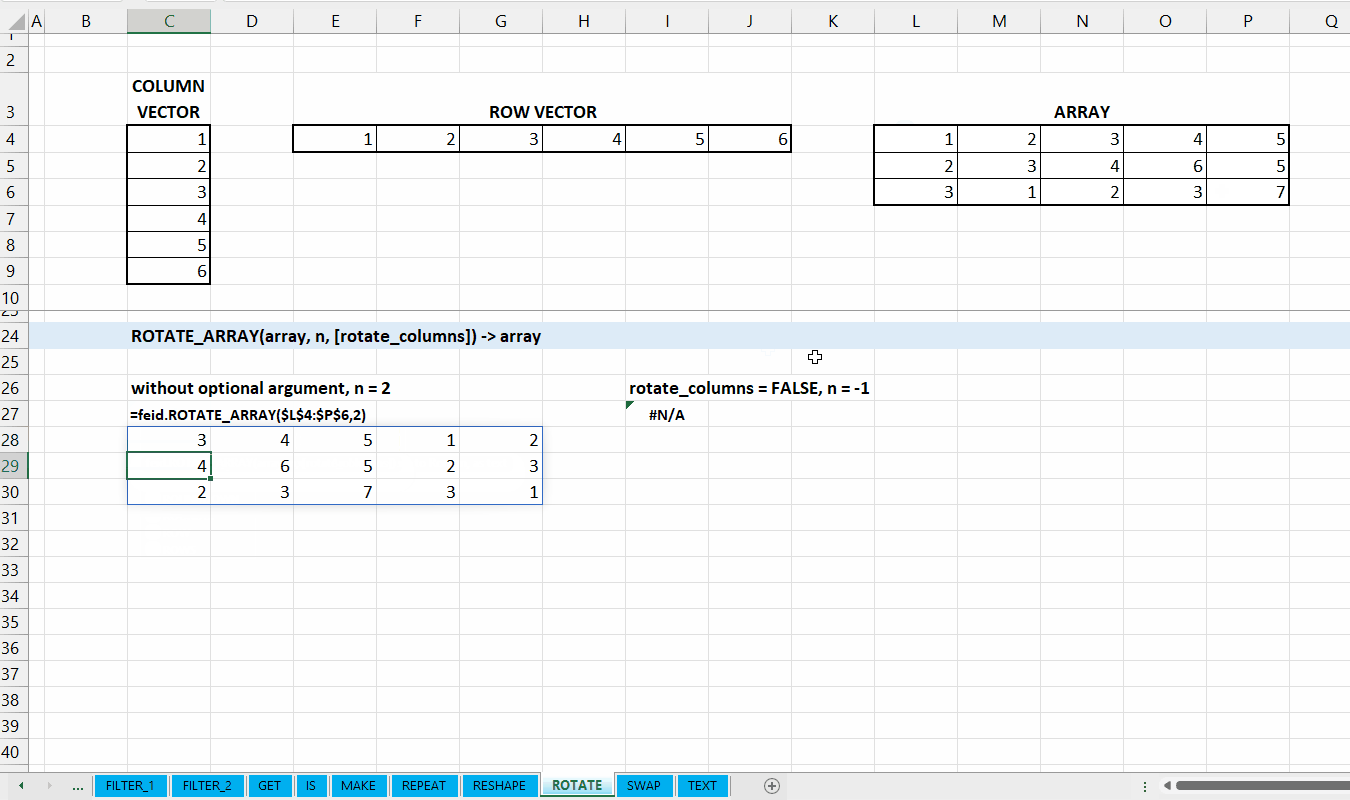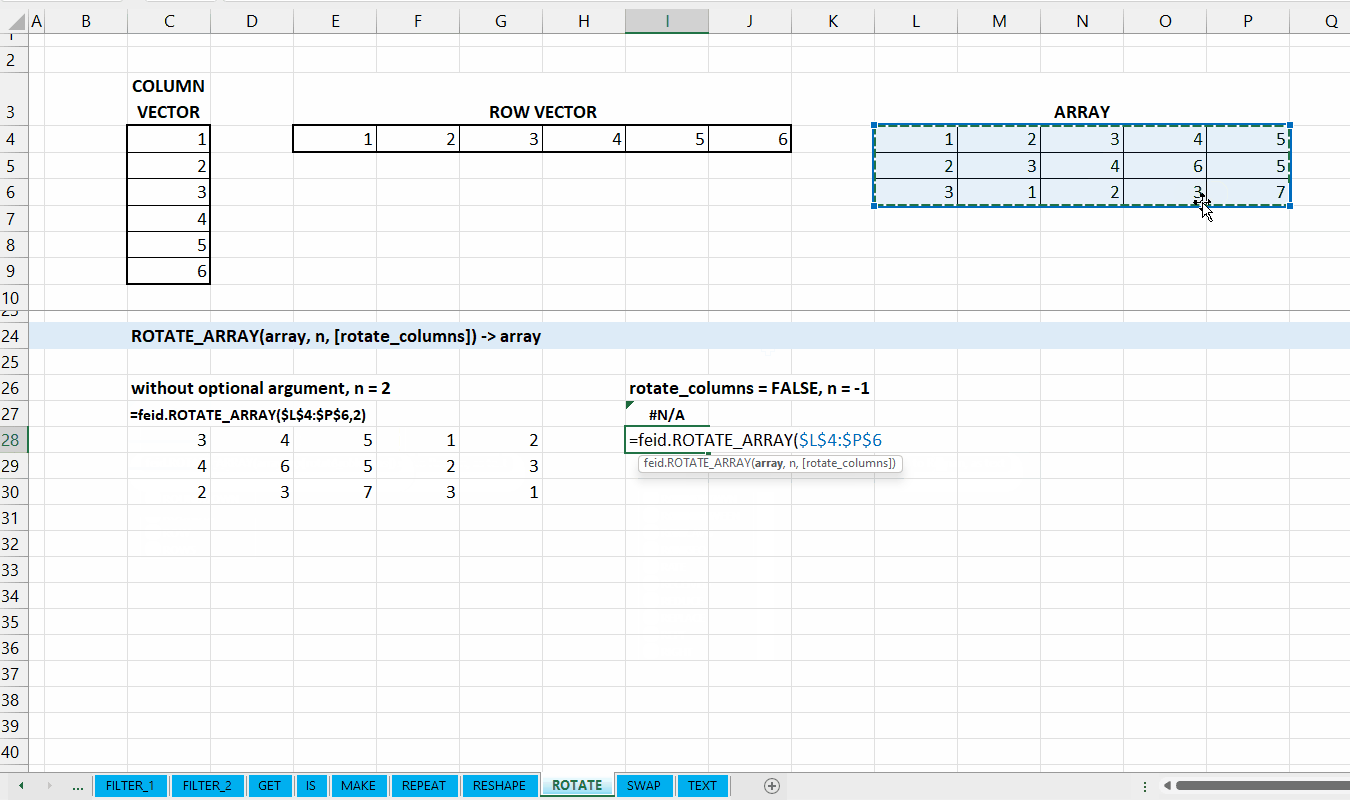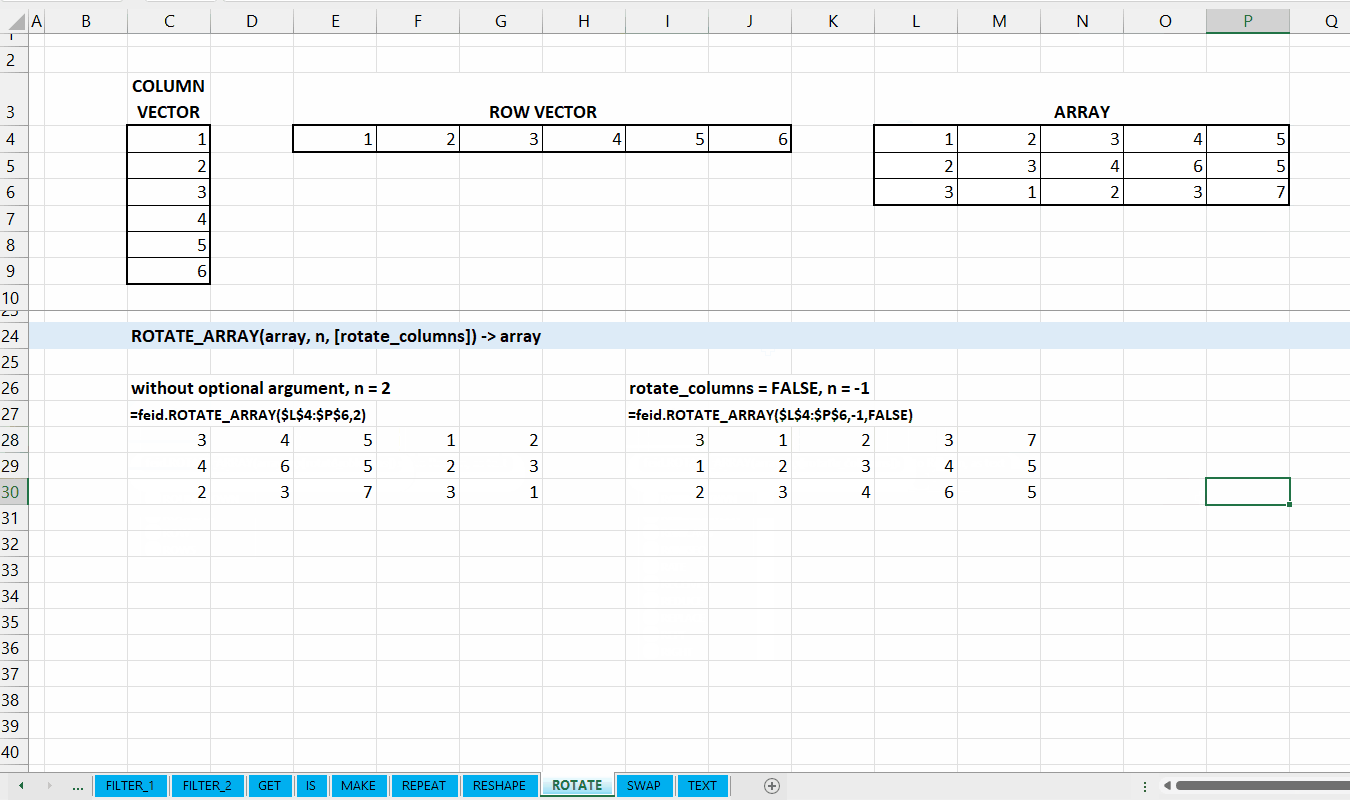
ROTATE_ARRAY()
Fungsi ROTATE_ARRAY(array, num_rotation, [rotate_columns]) digunakan untuk menggeser/memutar elemen yang ada di array sebanyak num_rotation berdasarkan baris atau kolom.
Jumlah berapa kali vector diputar/digeser. Nilai negatif untuk digeser berlawanan arah.
[rotate_columns] := TRUE :: [TRUE | FALSE]
Nilai default yaitu TRUE. Jika TRUE, maka array diputar berdasarkan kolom. Jika FALSE, maka array diputar berdasarkan baris.
Gambar 9.3: Demonstrasi ROTATE_ARRAY()
Kategori SWAP_*
Kategori SWAP_* merupakan kumpulan fungsi yang digunakan untuk mengganti atau mengubah posisi elemen atau vector. Hubungan antar fungsi di kategori ini bisa dilihat di Gambar 10.1.
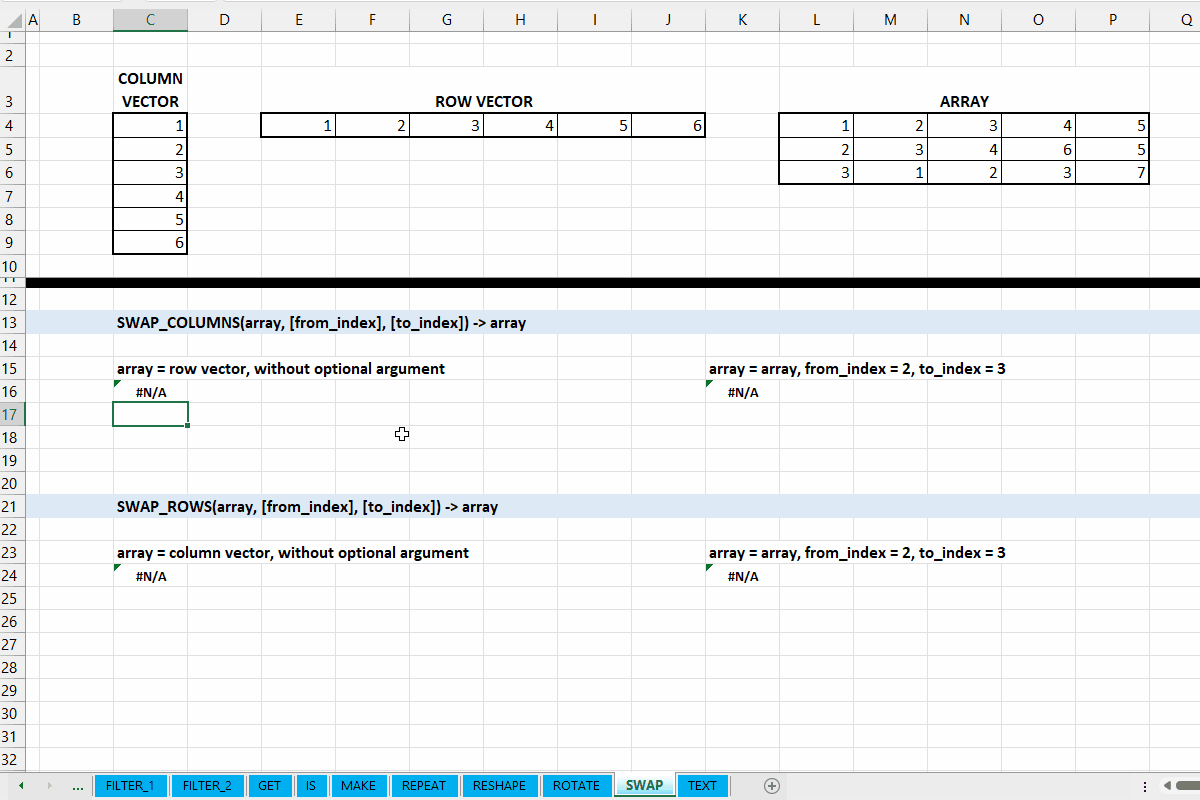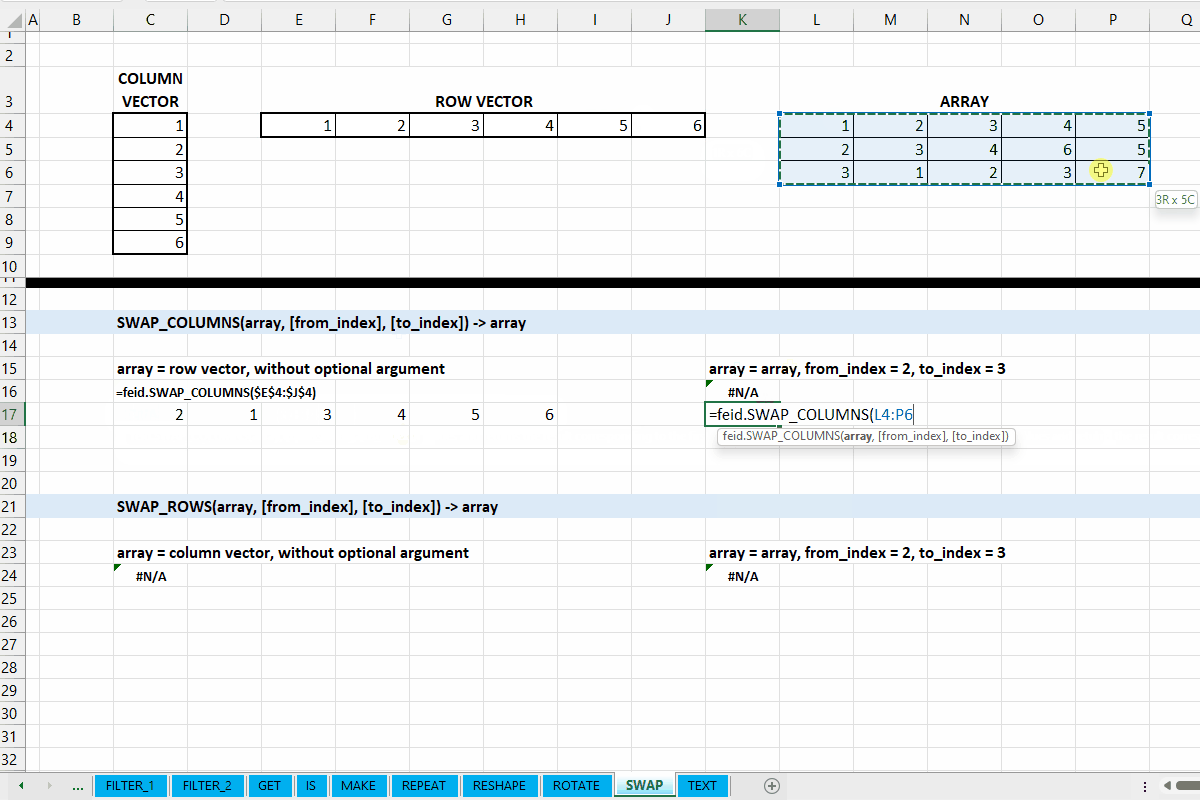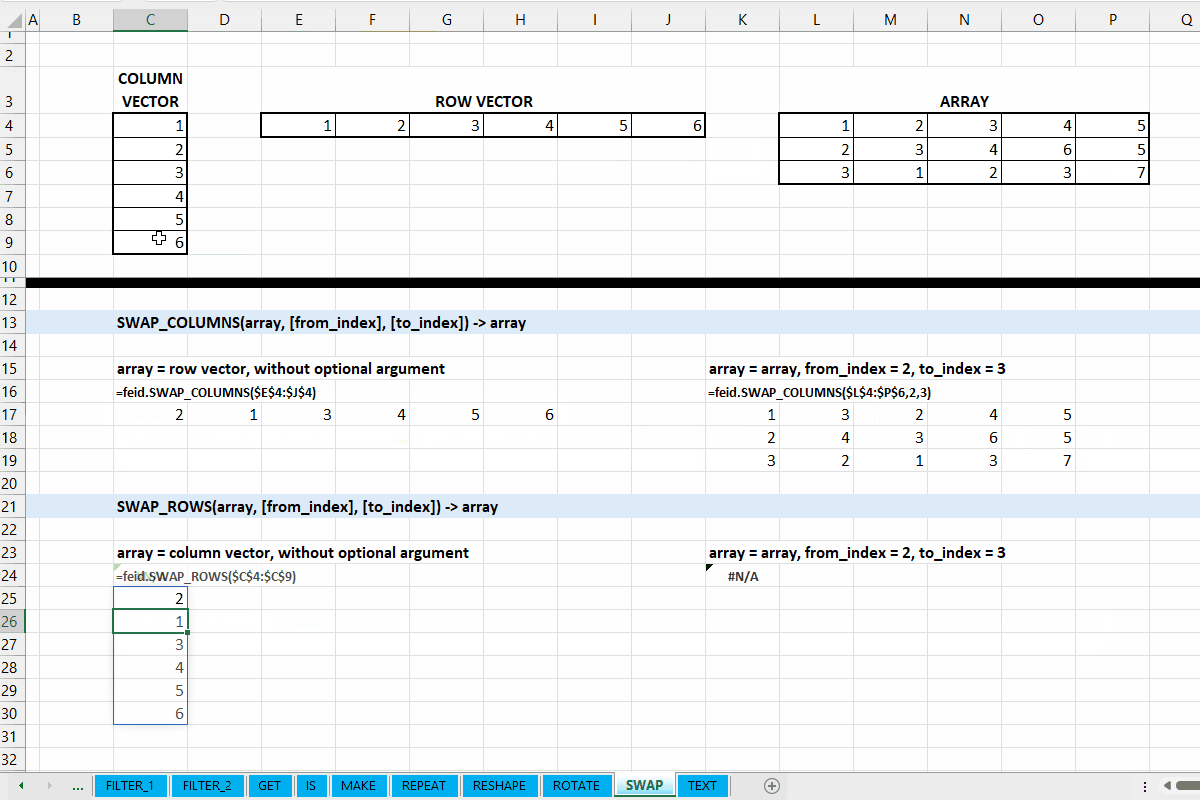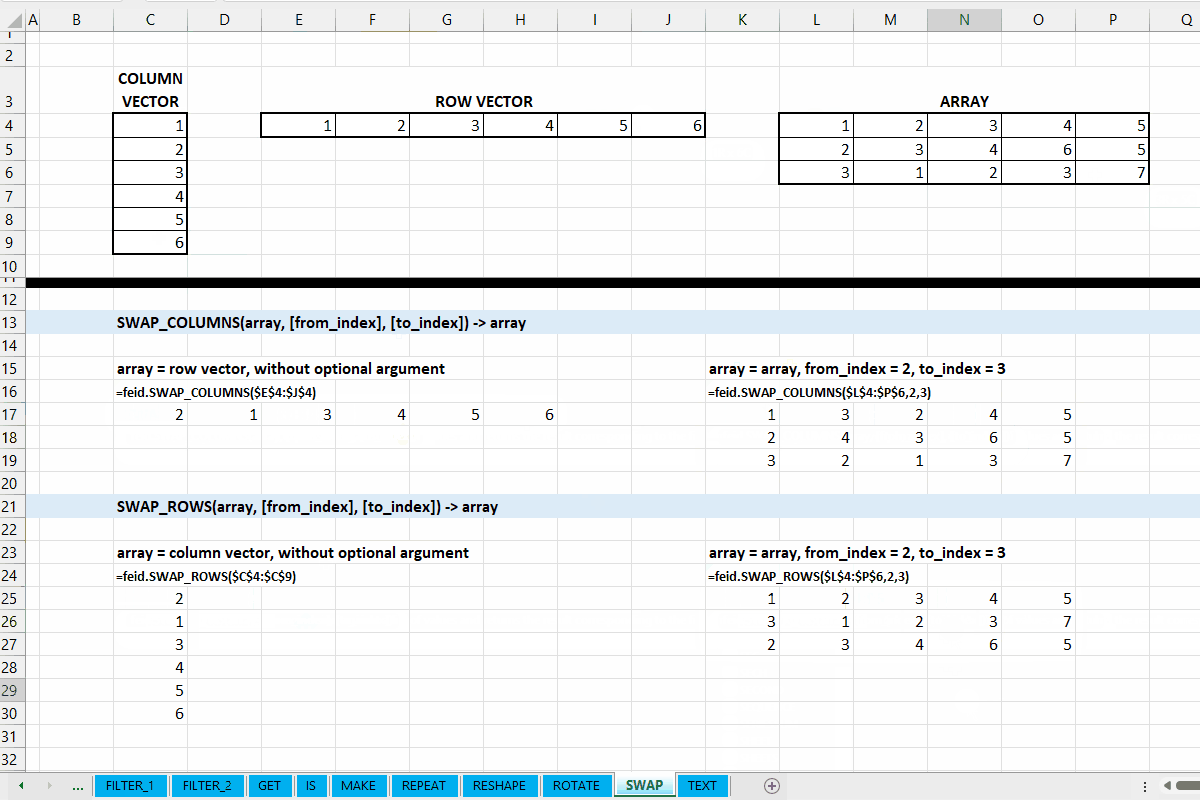
Fungsi SWAP_COLUMNS(array, [from_index], [to_index]) digunakan untuk menukar posisi kolom ke-from_index dengan kolom ke-to_index.
Syntax
SWAP_COLUMNS(array, [from_index], [to_index])
Output
vector atau array
array := [row vector | array]
Data dapat berupa array atau row vector.
[from_index] := 1 :: [integer]
(Change in v0.3.1). Nilai default yaitu 1. Posisi index kolom yang ingin dipindahkan. Jika menggunakan indeks negatif, maka posisi diambil dari belakang.
[to_index] := -1 :: [integer]
(Change in v0.3.1). Nilai default yaitu -1. Posisi index tujuan kolom. Jika menggunakan indeks negatif, maka posisi diambil dari belakang.
SWAP_ROWS()
Fungsi SWAP_ROWS(array, [from_index], [to_index]) digunakan untuk menukar posisi baris ke-from_index dengan baris ke-to_index.
Syntax
SWAP_COLUMNS(array, [from_index], [to_index])
Output
vector atau array
array := [column vector | array]
Data dapat berupa array atau column vector.
[from_index] := 1 :: [integer]
(Change in v0.3.1). Nilai default yaitu 1. Posisi index baris yang ingin dipindahkan. Jika menggunakan indeks negatif, maka posisi diambil dari belakang.
[to_index] := -1 :: [integer]
(Change in v0.3.1). Nilai default yaitu -1. Posisi index tujuan baris. Jika menggunakan indeks negatif, maka posisi diambil dari belakang.
Gambar 10.2: Demonstrasi SWAP_COLUMNS() dan SWAP_ROWS()
Kategori TEXT_*
Kategori TEXT_* merupakan kumpulan fungsi yang digunakan untuk memproses data teks. Hubungan antar fungsi di kategori ini bisa dilihat di Gambar 11.1.
Fungsi TEXT_SPLIT_VECTOR(text_vector, [col_delimiter], [row_delimiter], [ignore_empty], [match_mode], [pad_with], [replace_na]) merupakan fungsi pengembangan lanjutan dari TEXTSPLIT() yang mampu menerima input data berupa vector dan menghasilkan dalam bentuk dynamic array.
Nilai default yaitu " " (spasi). Teks pemisah untuk setiap kolomnya.
[row_delimiter] := "" :: [text]
(Change in v0.3.1). Nilai default yaitu "" (tidak ada). Teks pemisah untuk setiap barisnya.
[ignore_empty] := FALSE :: [TRUE | FALSE]
Tentukan TRUE untuk mengabaikan pemisah berurutan. Default ke FALSE, yang membuat sel kosong. Opsional.
[match_mode] := 0 :: [0 | 1]
Tentukan 1 untuk melakukan kecocokan yang tidak peka huruf besar kecil. Default ke 0, yang melakukan kecocokan peka huruf besar kecil. Opsional.
[pad_with] := #N/A :: [text | number]
Nilai untuk mengalihkan hasil. Defaultnya adalah #N/A.
[replace_na] := #N/A :: [text | number]
(New in v0.3.1). Nilai untuk menggantikan nilai #N/A dari hasil akhir. Defaultnya adalah #N/A. Nilai #N/A yang ada dikarenakan proses VSTACK() yang memiliki dimensi hasil TEXTSPLIT() yang berbeda-beda.
Deskripsi ignore_empty, match_mode, dan pad_with diambil dari halaman Fungsi TEXTSPLIT.
Limitasi TEXT_SPLIT_VECTOR()
Hindari menggunakan TEXT_SPLIT_VECTOR() dengan jumlah baris yang banyak ataupun dimensi output yang besar. Pastikan hasil output fungsi memiliki dimensi yang kecil seperti jumlah kolom \(\le 10\) dan jumlah baris \(\le 1,000\).
Ukuran text_vector masih bisa lebih besar dari batasan diatas, akan tetapi disarankan untuk penggunaan TEXT_SPLIT_VECTOR() selalu bertahap, yaitu dari jumlah baris yang sedikit sampai jumlah baris optimal yang tidak menampilkan error atau crash.
Jika melebihi kemampuan, akan menghasilkan nilai error berupa #NUM / #CALC.
Gambar 11.2: Demonstrasi TEXT_SPLIT_VECTOR (outdated)
Fungsi feidlambda v0.3 memiliki \(9\) kategori dengan total \(23\) fungsi utama dan pendukung. Dengan perombakan struktur dan penamaan dari v0.2 ke v0.3, harapannya v0.3 sudah memiliki struktur dan penamaan yang konsisten sehingga untuk memproduksi fungsi ataupun fitur barunya lebih cepat di versi-versi berikutnya.
Jika ada ide untuk pengembangan feidlambda atau fungsi baru bisa langsung membuat isu di github. Dan jika bertemu masalah saat penggunaan feidlambda v0.3, bisa juga membuat isu di github.
Changelog
2022-01-13 (v0.3.1)
Perubahan fungsi utama:
Perubahan FILTER_MINMAX_ARRAY():
Menambah optional argumen take_first_only.
Mengganti nama argumen: with_labels -> with_label.
Penyesuaian _RECURSIVE_FILTER_MINMAX() dengan posisi dan opsi argumen terbaru.
Perubahan GET_INDEX_2D():
Mengubah nama argumen: return_order_only -> return_as_order.
Perubahan RESHAPE_BY_COLUMNS():
Mengubah hasil error menjadi NA().
Perubahan ROTATE_VECTOR() dan ROTATE_ARRAY():
Mengubah nama argumen: n -> num_rotation.
Perubahan SWAP_COLUMNS() dan SWAP_ROWS():
Argumen from_index dan to_index dapat menggunakan indeks negatif.
Nilai defaultto_index menjadi -1.
Perubahan TEXT_SPLIT_VECTOR():
Mengubah metode menjadi recursive.
Mengubah nama argumen: text_delimiter -> col_delimiter.
Menambah optional argumen replace_na.
Perubahan fungsi pendukung:
Perubahan FILTER_FUNC_COLUMN():
Mengganti nama argumen: col -> column_index.
Menukar posisi argumen label_col dan with_label.
Menambah optional argumen take_first_only.
Perubahan FILTER_MINMAX_COLUMN():
Mengganti nama argumen: col -> column_index.
Menukar posisi argumen label_col dan with_label.
Menambah optional argumen take_first_only.
Penyesuaian FILTER_FUNC_COLUMN() dengan posisi dan opsi argumen terbaru.
Perubahan _RECURSIVE_FILTER_MINMAX():
Mengubah posisi argumen label_col dan with_label.
Penyesuaian FILTER_MINMAX_COLUMN() dengan posisi dan opsi argumen terbaru.